Manual
Introduction
nopaque is a web-based digital working environment. It implements a workflow based on the research process in the humanities and supports its users in processing their data in order to subsequently apply digital analysis methods to them. All processes are implemented in a specially provided cloud environment with established open source software. This always ensures that no personal data of the users is disclosed.
Registration and Log in
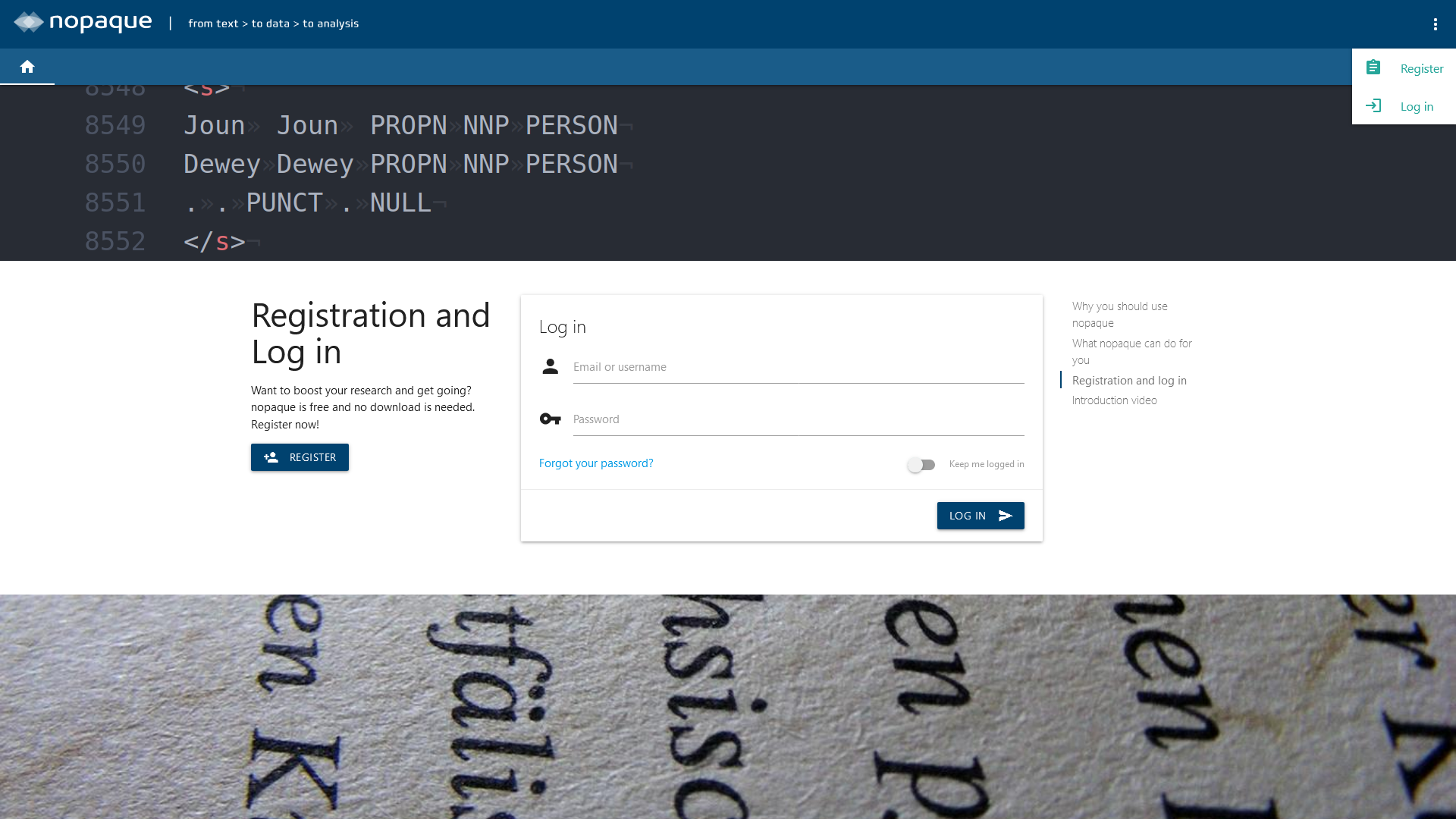
Before you can start using the web platform, you need to create a user account. This requires only a few details: just a user name, an e-mail address and a password are needed. In order to register yourself, fill out the form on the registration page. After successful registration, the created account must be verified. To do this, follow the instructions given in the automatically sent e-mail. Afterwards, you can log in as usual with your username/email address and password in the log-in form located next to the registration button.
Dashboard
The dashboard provides a central overview of all resources assigned to the user. These are corpora and created jobs. Corpora are freely composable annotated text collections and jobs are the initiated file processing procedures. One can search for jobs as well as corpus listings using the search field displayed above them.
A corpus is a collection of texts that can be analyzed using the Corpus Analysis service. All texts must be in the verticalized text file format, which can be obtained via the Natural Language Processing service. It contains, in addition to the text, further annotations that are searchable in combination with optional metadata that can be added during your analysis.
A job is a construct that represents the execution of a service. It stores input files, output files, processing status, and options selected during creation. After submitting a job, you get redirected to a job overview page. This can be accessed again via the job list on the dashboard. Jobs will be deleted three months after creation, so we encourage you to download the results after a job is completed.
Services
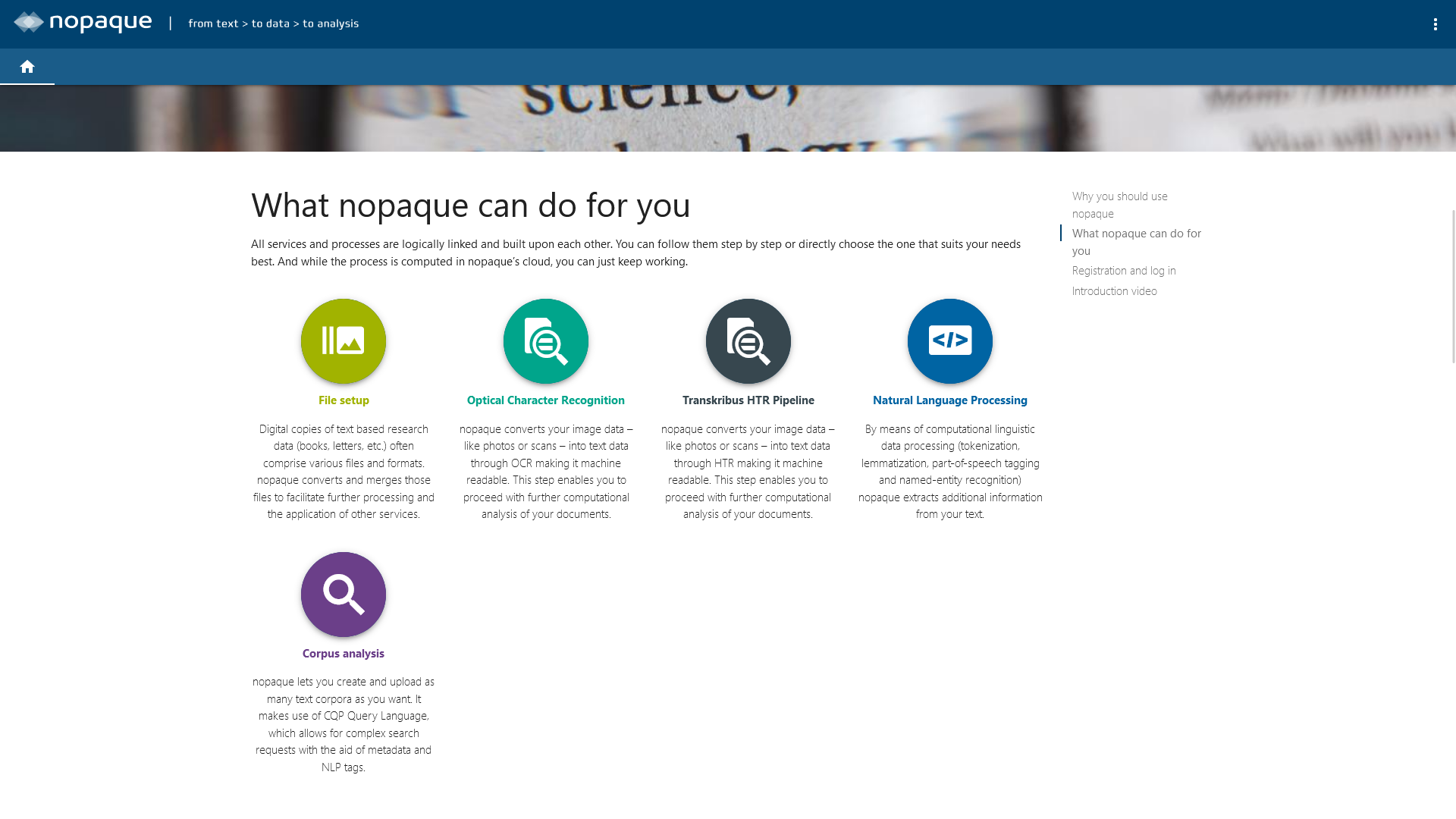
nopaque was designed from the ground up to be modular. This modularity means that the offered workflow provides variable entry and exit points, so that different starting points and goals can be flexibly addressed. Each of these modules are implemented in a self-contained service, each of which represents a step in the workflow. The services are coordinated in such a way that they can be used consecutively. The order can either be taken from the listing of the services in the left sidebar or from the roadmap (accessible via the pink compass in the upper right corner). All services are versioned, so the data generated with nopaque is always reproducible.
File Setup
The File Setup Service bundles image data, such as scans and photos, together in a handy PDF file. To use this service, use the job form to select the images to be bundled, choose the desired service version, and specify a title and description. Please note that the service sorts the images into the resulting PDF file based on the file names. So naming the images correctly is of great importance. It has proven to be a good practice to name the files according to the following scheme: page-01.png, page-02.jpg, page-03.tiff, etc. In general, you can assume that the images will be sorted in the order in which the file explorer of your operating system lists them when you view the files in a folder sorted in ascending order by file name.
Optical Character Recognition (OCR)
Coming soon...
Handwritten Text Recognition (HTR)
Coming soon...
Natural Language Processing (NLP)
Coming soon...
Corpus Analysis
With the corpus analysis service, it is possible to create a text corpus and then explore it in an analysis session. The analysis session is realized on the server side by the Open Corpus Workbench software, which enables efficient and complex searches with the help of the CQP Query Language.
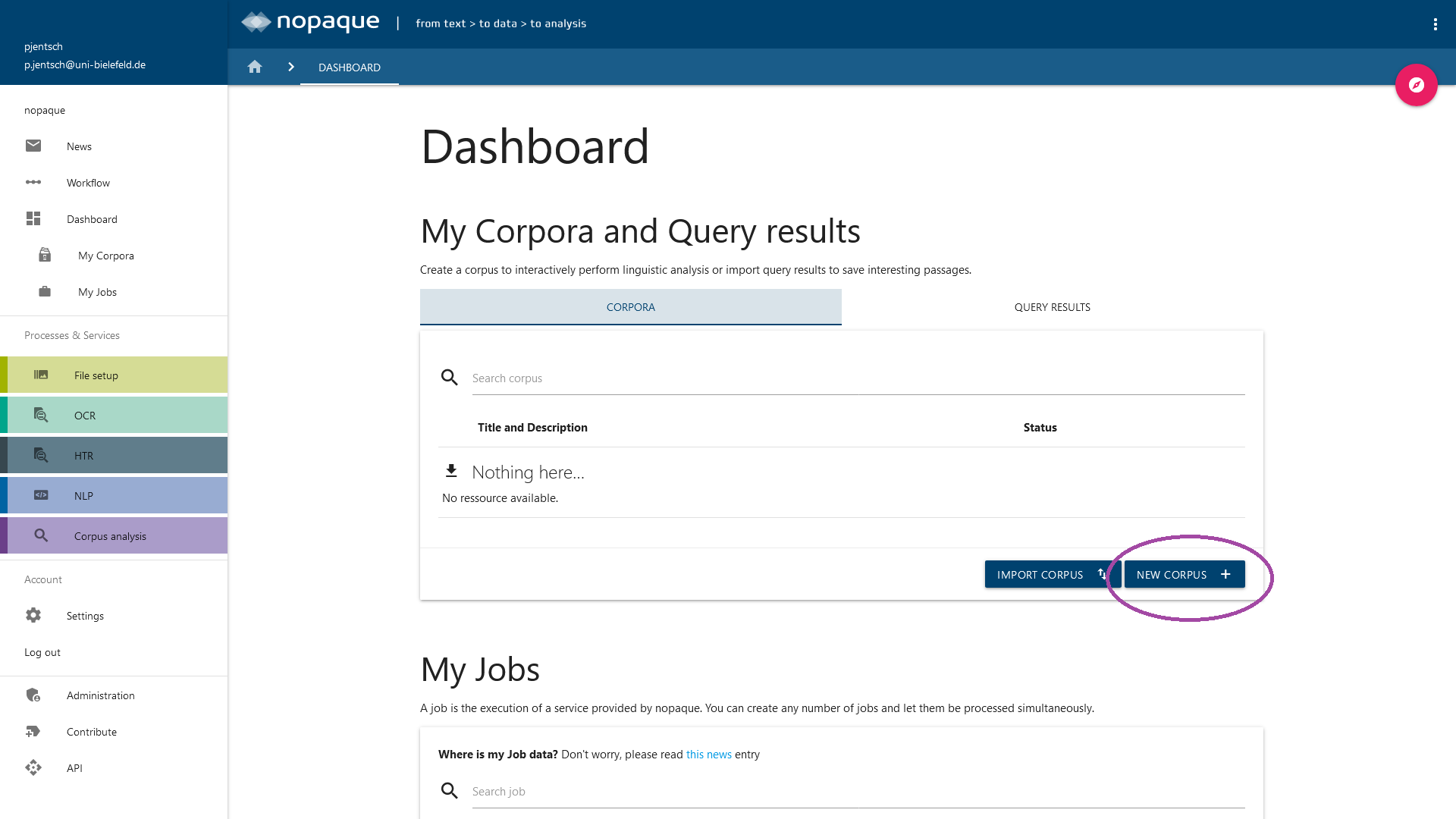
To create a corpus, you can use the "New Corpus" button, which can be found on both the Corpus Analysis Service page and the Dashboard below the corpus list. Fill in the input mask to Create a corpus. After you have completed the input mask, you will be automatically taken to the corpus overview page (which can be called up again via the corpus lists) of your new and accordingly still empty corpus.
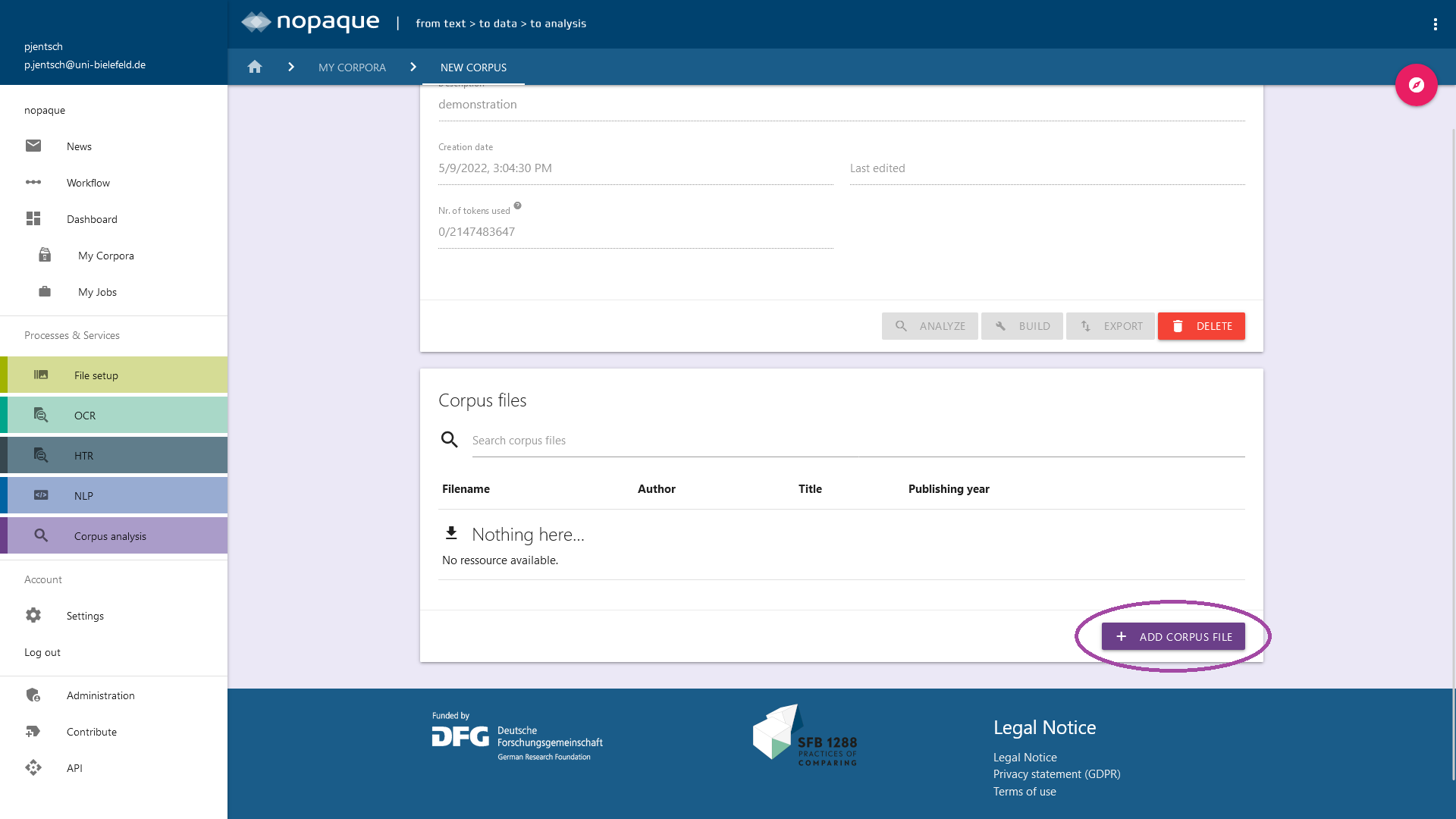
Now you can add texts in vrt format (results of the NLP service) to your new corpus. To do this, use the "Add Corpus File" button and fill in the form that appears. You will get the possibility to add metadata to each text. After you have added all the desired texts to the corpus, the corpus must be prepared for the analysis, this process can be initiated by clicking on the "Build" button. On the corpus overview page you can always see information about the current status of the corpus in the upper right corner. After the build process the status should be "built".
Analyze a corpus
After you have created and built a corpus, it can be analyzed. To do this, use the button labeled Analyze. The corpus analysis currently offers two modules, the Reader and the Concordance module. The reader module can be used to read your tokenized corpus in different ways. You can select a token representation option, it determines the property of a token to be shown. You can for example read your text completly lemmatized. You can also change the way of how a token is displayed, by using the text style switch. The concordance module offers some more options regarding the context size of search results. If the context does not provide enough information you can hop into the reader module by using the magnifier icon next to a match.
CQP Query Language
Within the Corpus Query Language, a distinction is made between two types of annotations: positional attributes and structural attributes. Positional attributes refer to a token, e.g. the word "book" is assigned the part-of-speech tag "NN", the lemma "book" and the simplified part-of-speech tag "NOUN" within the token structure. Structural attributes refer to text structure-giving elements such as sentence and entity markup. For example, the markup of a sentence is represented in the background as follows:
<s> structural attribute
word pos lemma simple_pos positional attribute
<ent type="PERSON"> structural attribute
word pos lemma simple_pos positional attribute
word pos lemma simple_pos positional attribute
</ent> structural attribute
word pos lemma simple_pos positional attribute
</s> structural attribute
Positional attributes
Before you can start searching for positional attributes (also called tokens), it is necessary to know what properties they contain.
- word: The string as it is also found in the original text
-
pos: A code for the word type, also called POS tag
- IMPORTANT: POS tags are language-dependent to best reflect language-specific properties.
- The codes (= tagsets) can be taken from the Corpus Analysis Concordance page.
- lemma: The lemmatized representation of the word
-
simple_pos: A simplified code for the word type that covers fewer categories than the pos property, but is the same across languages.
- The codes (= tagsets) can be taken from the Corpus Analysis Concordance page.
Searching for positional attributes
Token with no condition on any property (also called wildcard token)
[]; Each token matches this patternToken with a condition on its word property
[word="begin"]; “begin”[word="begin" %c]; same as above but ignores caseToken with a condition on its lemma property
[lemma="begin"]; “begin”, “began”, “beginning”, …[lemma="begin" %c]; same as above but ignores caseToken with a condition on its simple_pos property
[simple_pos="VERB"]; “begin”, “began”, “beginning”, …Token with a condition on its pos property
[pos="VBG"]; “begin”, “began”, “beginning”, …
Look for words with a variable character (also called wildcard character)
[word="beg.n"]; “begin”, “began”, “begun” ^ the dot represents the wildcard characterToken with two conditions on its properties, where both must be fulfilled (AND operation)
[lemma="be" & simple_pos="VERB"]; Lemma “be” and simple_pos is Verb ^ the ampersand represents the and operationToken with two conditions on its properties, where at least one must be fulfilled (OR operation)
[simple_pos="VERB" | simple_pos="ADJ"]; simple_pos VERB or simple_pos ADJ (adjective) ^ the line represents the or operationSequences
[simple_pos="NOUN"] [simple_pos="VERB"]; NOUN -> VERB[simple_pos="NOUN"] [] [simple_pos="VERB"]; NOUN -> wildcard token -> VERB
Incidence modifiers
Incidence Modifiers are special characters or patterns, that control how often a character/token that stands in front of it should occur.
- +: One or more occurrences of the character/token before
- *: Zero or more occurrences of the character/token before
- ?: Zero or one occurrences of the character/token before
- {n}: Exactly n occurrences of the character/token before
- {n,m}: Between n and m occurrences of the character/token before
[word="beg.+"]; “begging”, “begin”, “began”, “begun”, …[word="beg.*"]; “beg”, “begging”, “begin”, “begun”, …[word="beg?"]; “be”, “beg”[word="beg.{2}"]; “begin”, “begun”, …[word="beg.{2,4}"]; “begging”, “begin”, “begun”, …[word="beg{2}.*"]; “begged”, “beggar”, …[simple_pos="NOUN"] []? [simple_pos="VERB"]; NOUN -> wildcard token (x0 or x1) -> VERB[simple_pos="NOUN"] []* [simple_pos="VERB"]; NOUN -> wildcard token (x0 or x1) -> VERB
Option groups
Find character sequences from a list of options.
[word="be(g|gin|gan|gun)"]; “beg”, “begin”, “began”, “begun” ^ ^ the braces indicate the start and end of an option groupStructural attributes
nopaque provides several structural attributes for query. A distinction is made between attributes with and without value.
- s: Annotates a sentence
-
ent: Annotates an entity
-
*ent_type: Annotates an entity and has as value a code that identifies the type of the entity.
- The codes (= tagsets) can be taken from the Corpus Analysis Concordance page.
-
*ent_type: Annotates an entity and has as value a code that identifies the type of the entity.
-
text: Annotates a text
- Note that all the following attributes have the data entered during the corpus creation as value.
- *text_address
- *text_author
- *text_booktitle
- *text_chapter
- *text_editor
- *text_institution
- *text_journal
- *text_pages
- *text_publisher
- *text_publishing_year
- *text_school
- *text_title
Searching for structural attributes
<ent> [] </ent>; A one token long entity of any type<ent_type="PERSON"> [] </ent_type>; A one token long entity of type PERSON<ent_type="PERSON"> []* </ent_type>; Entity of any length of type PERSON<ent_type="PERSON"> []* </ent_type> []* [simple_pos="VERB"] :: match.text_publishing_year="1991";Arbitrarily long entity of type PERSON -> Arbitrarily many tokens -> VERB but only within texts with publication year 1991Query Builder
Overview
The query builder can be accessed via "My Corpora" or "Corpus Analysis" in the sidebar options. Select the desired corpus and click on the "Analyze" and then "Concordance" buttons to open the query builder.
The query builder uses the Corpus Query Language (CQL) to help you make a query for analyzing your texts. In this way, it is possible to filter out various types of text parameters, for example, a specific word, a lemma, or you can set part-of-speech tags (pos) that indicate the type of word you are looking for (a noun, an adjective, etc.). In addition, you can also search for structural attributes, or specify your query for a token (word, lemma, pos) via entity typing. And of course, the different text parameters can be combined.
Tokens and structural attributes can be added by clicking on the "+" button
(the "input marker") in the input field or the labeled buttons below it. Elements
added are shown as chips. These can be reorganized using drag and drop. The input
marker can also be moved in this way. Its position shows where new elements will be added.
A "translation" of your query into Corpus Query Language (CQL) is shown below.
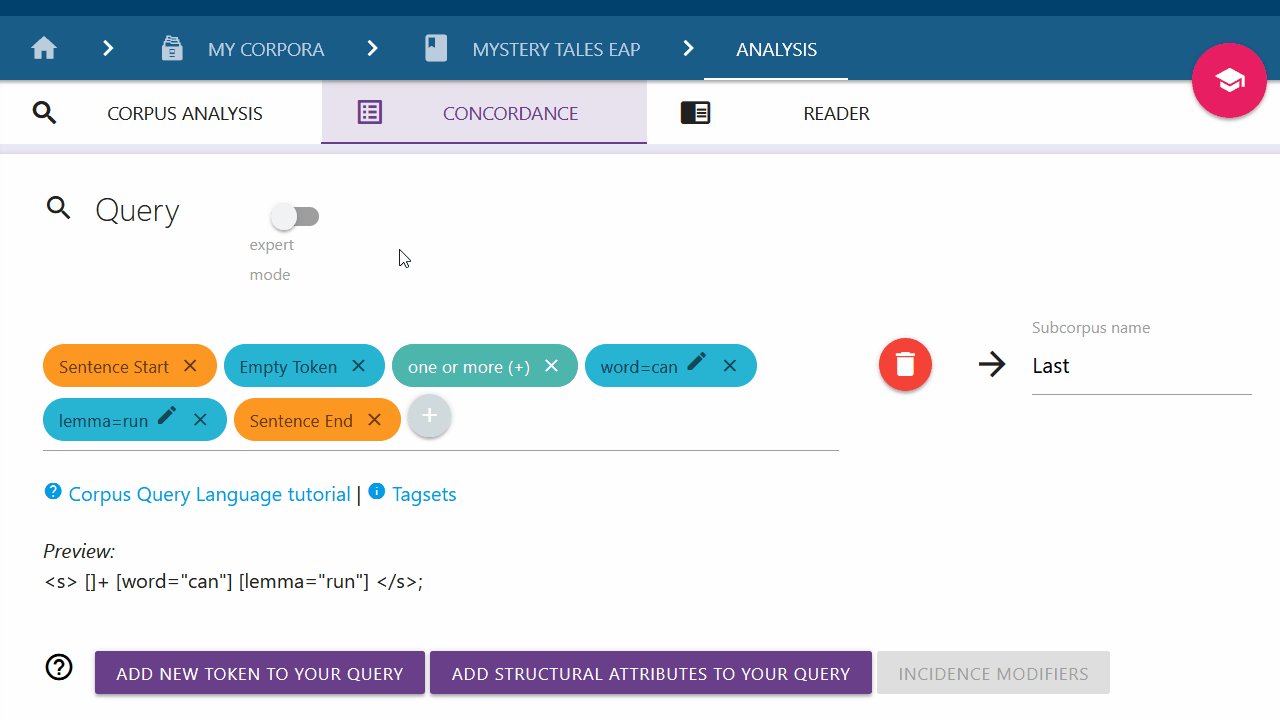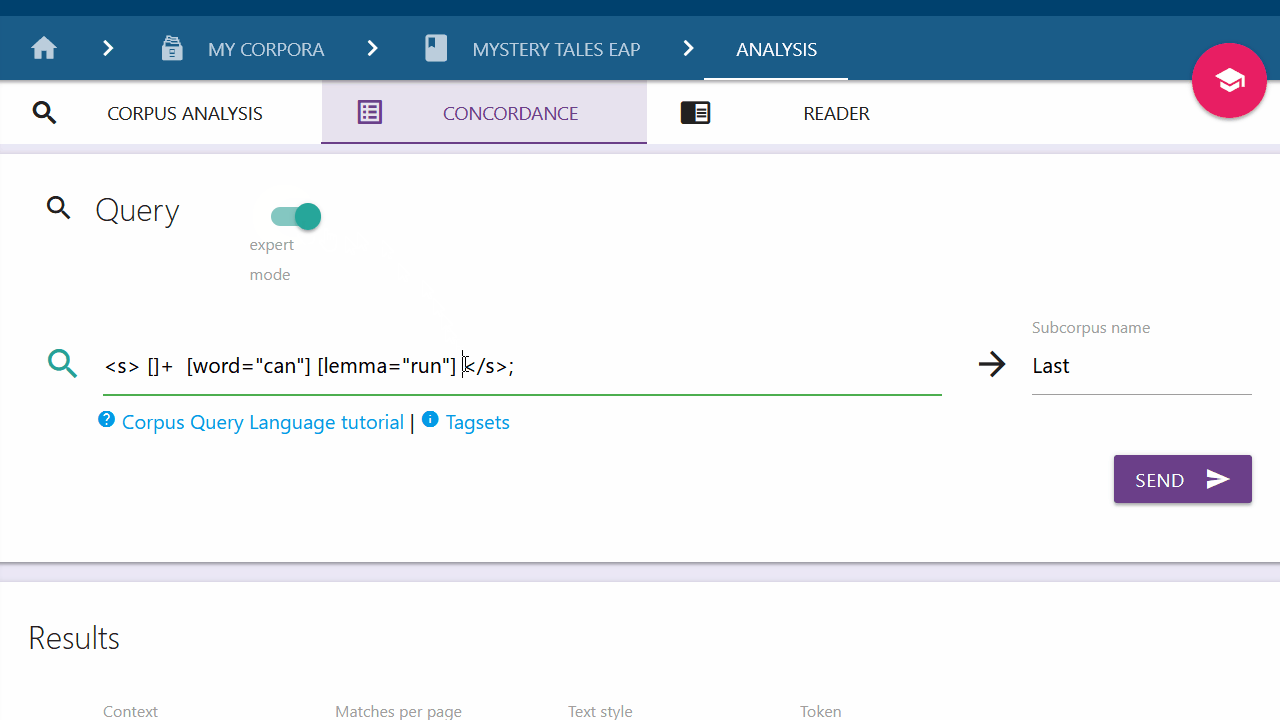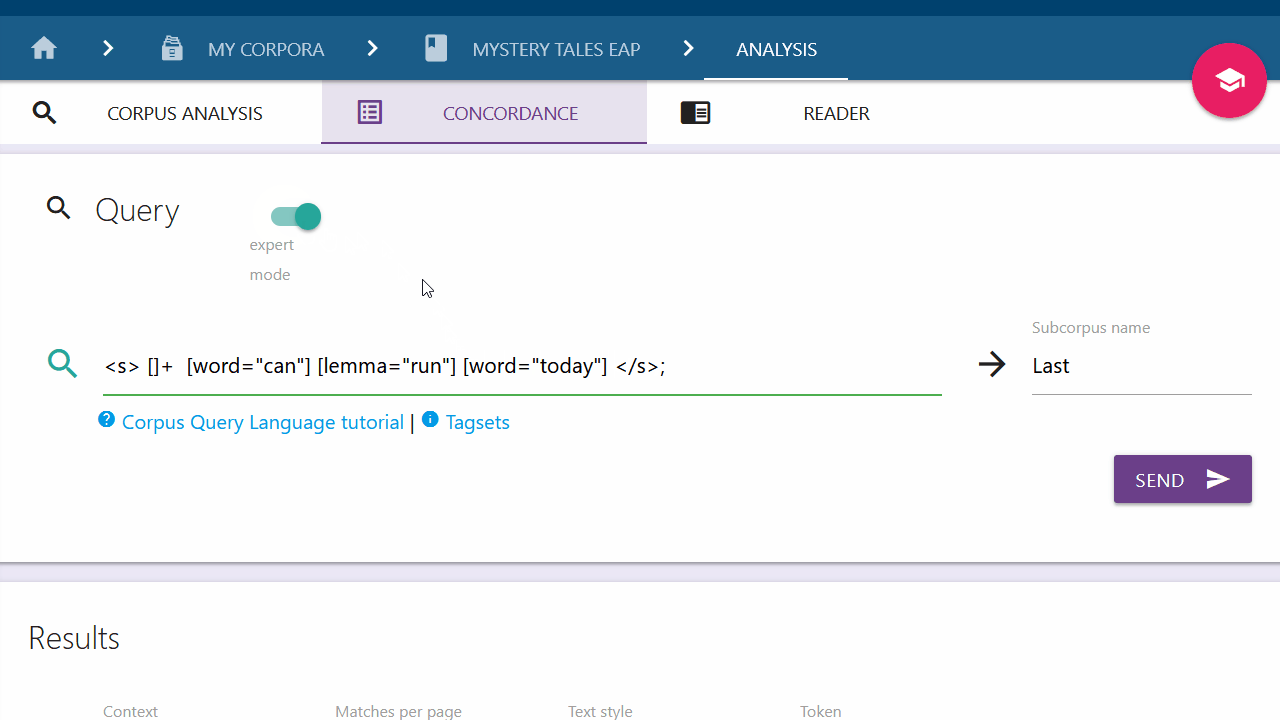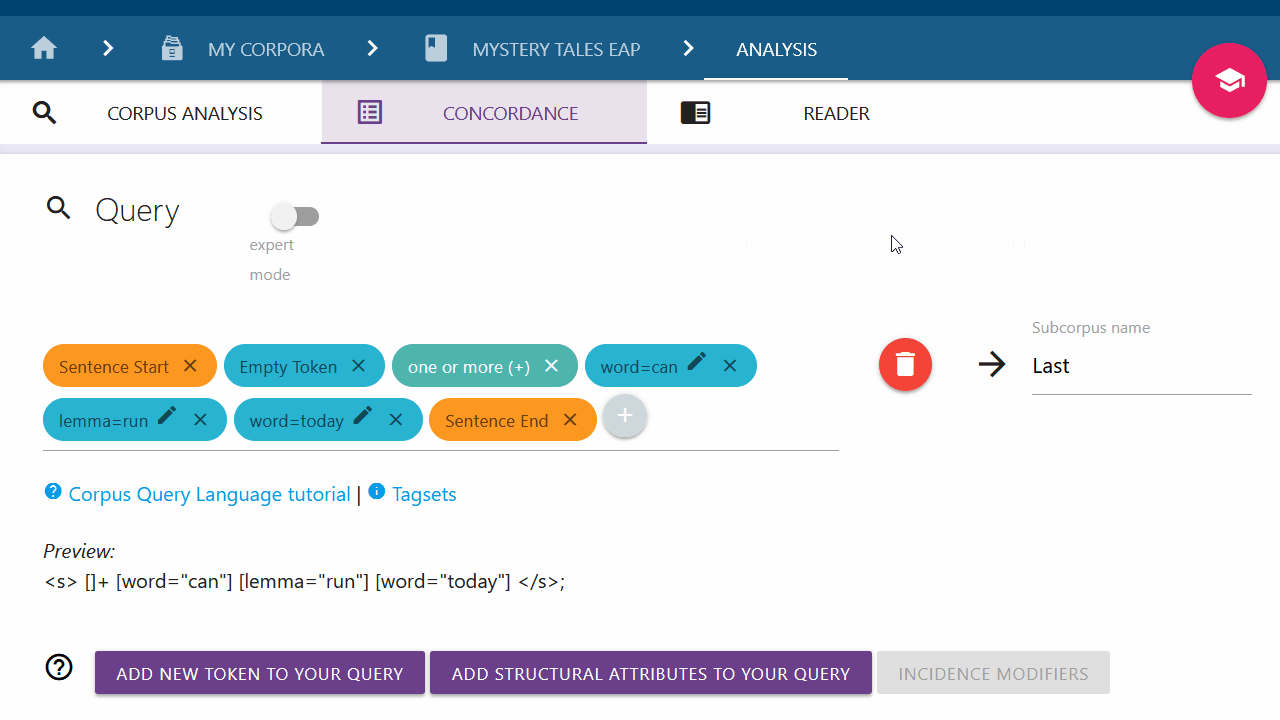
Advanced users can make direct use of the Corpus Query Language (CQL) by switching to "expert mode" via the toggle button.
The entire input field can be cleared using the red trash icon on the right.
Content
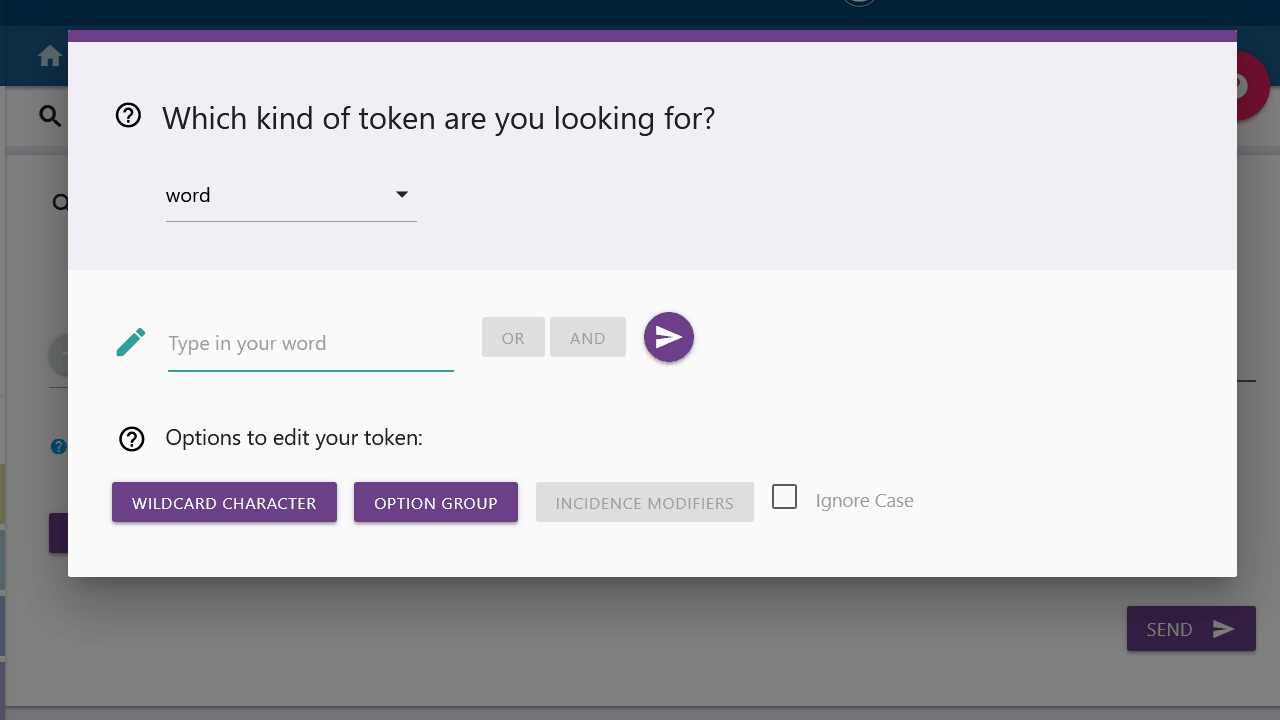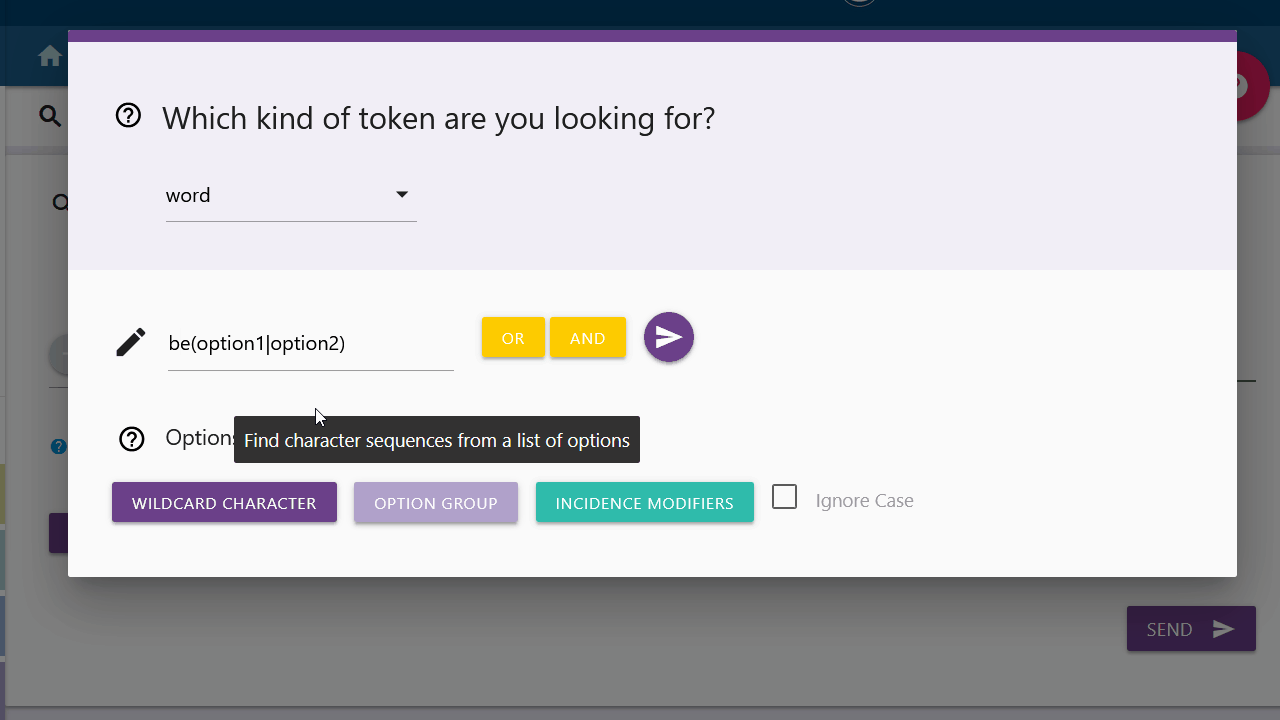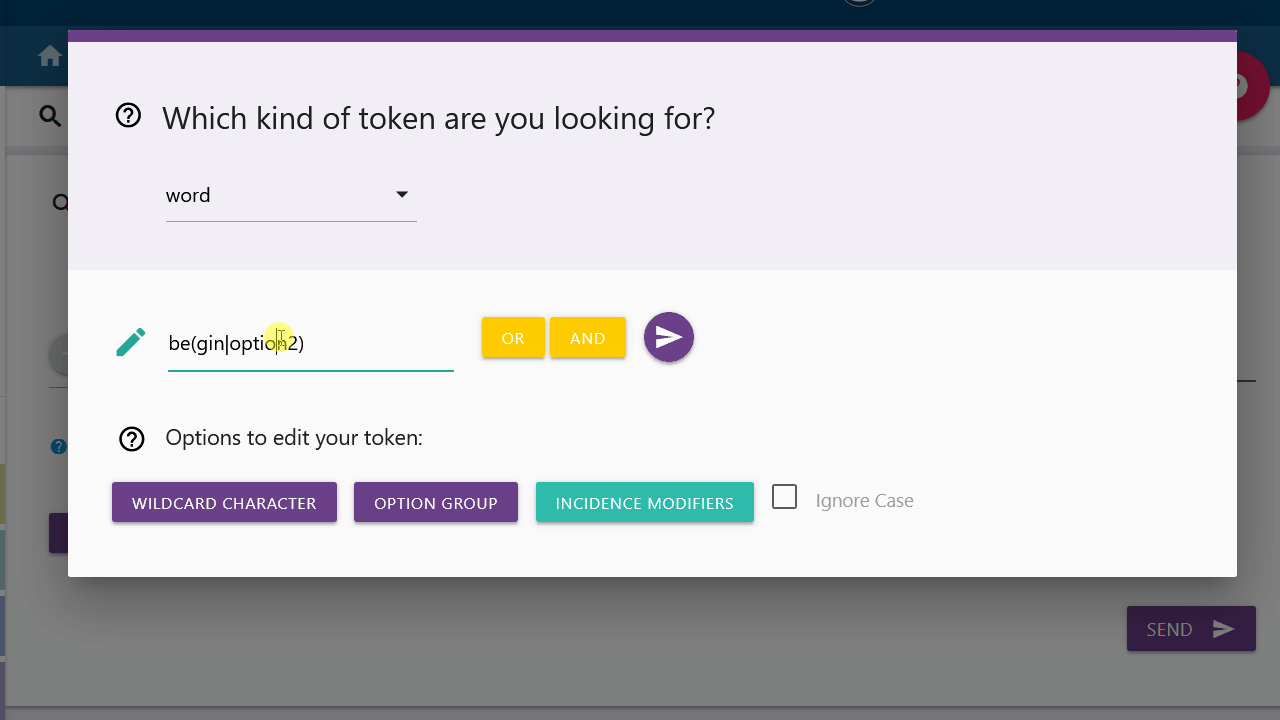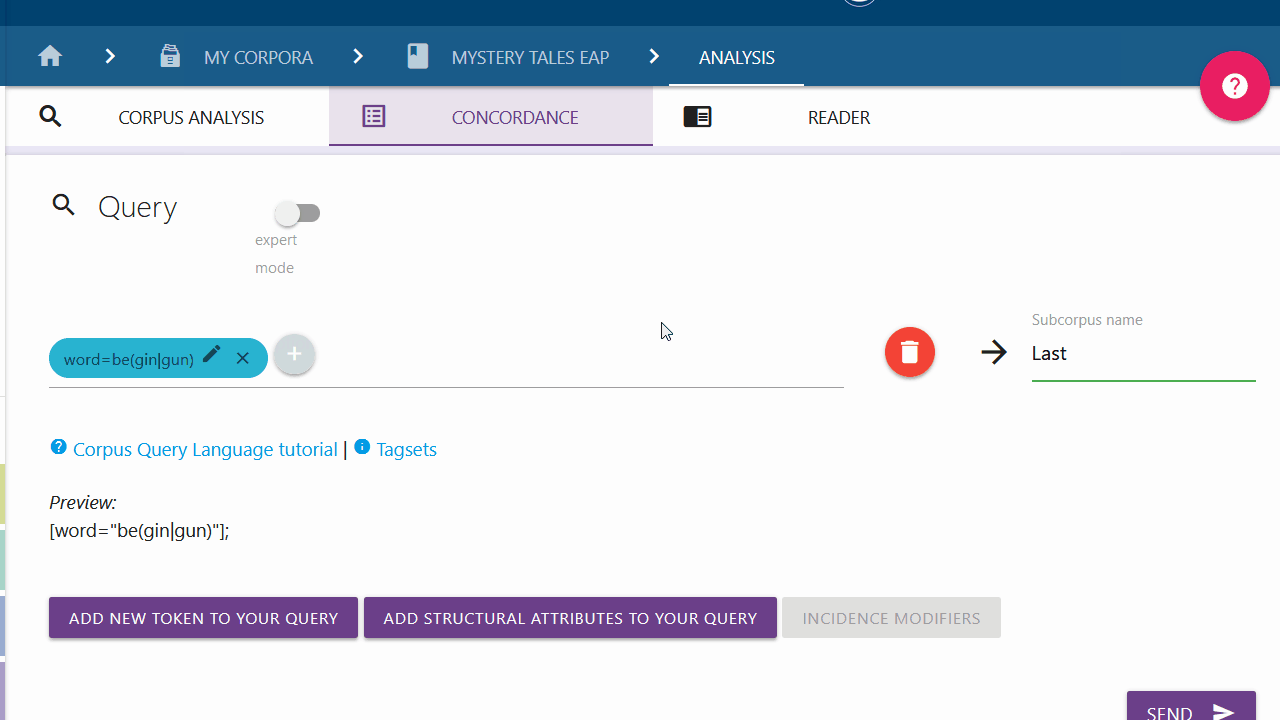
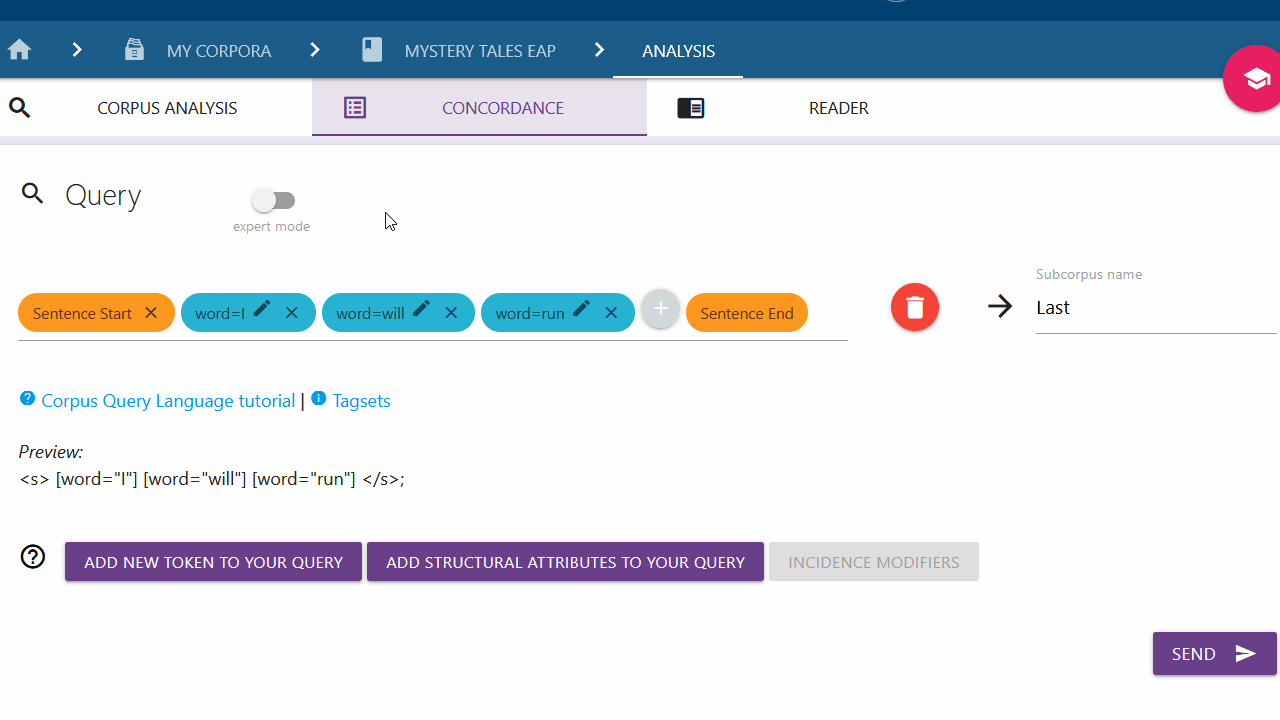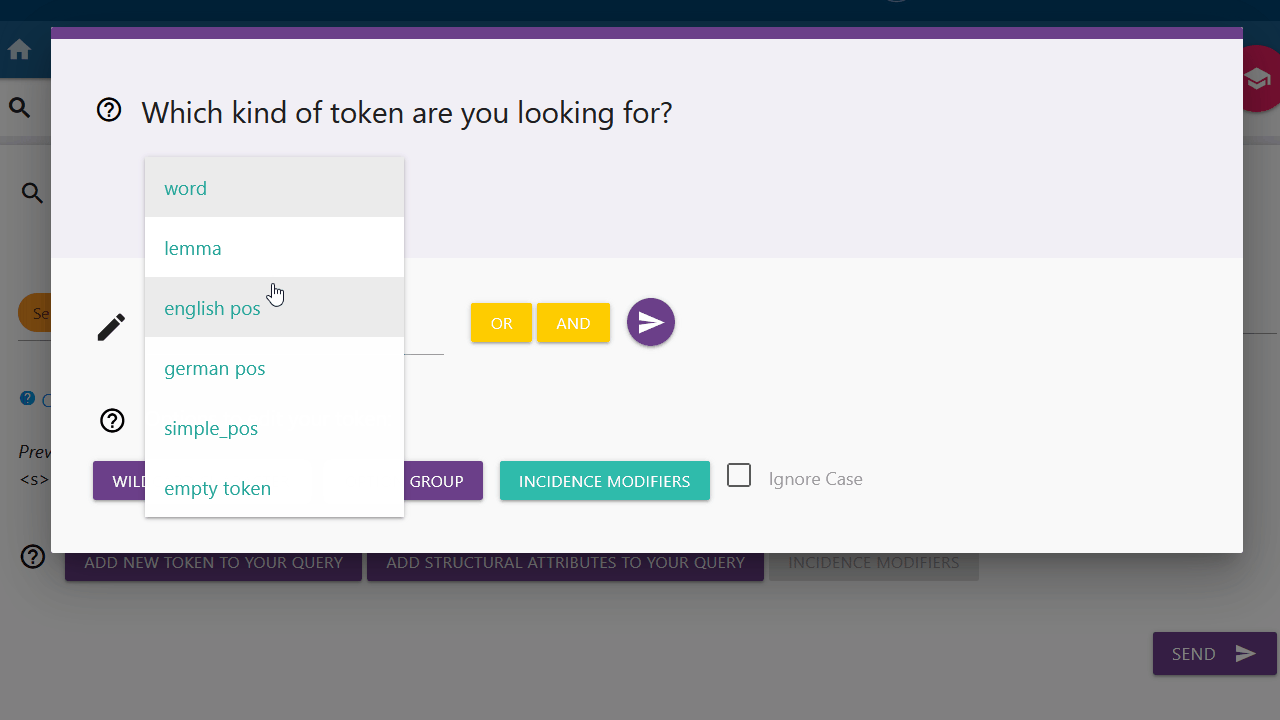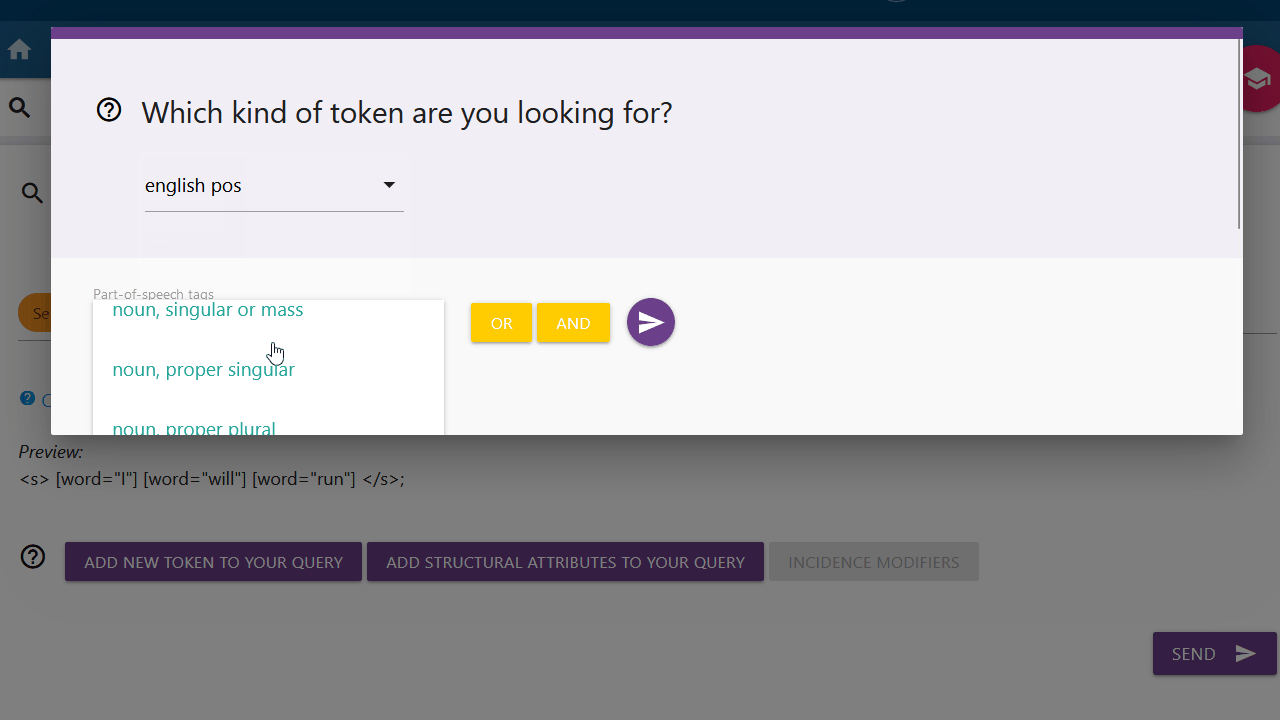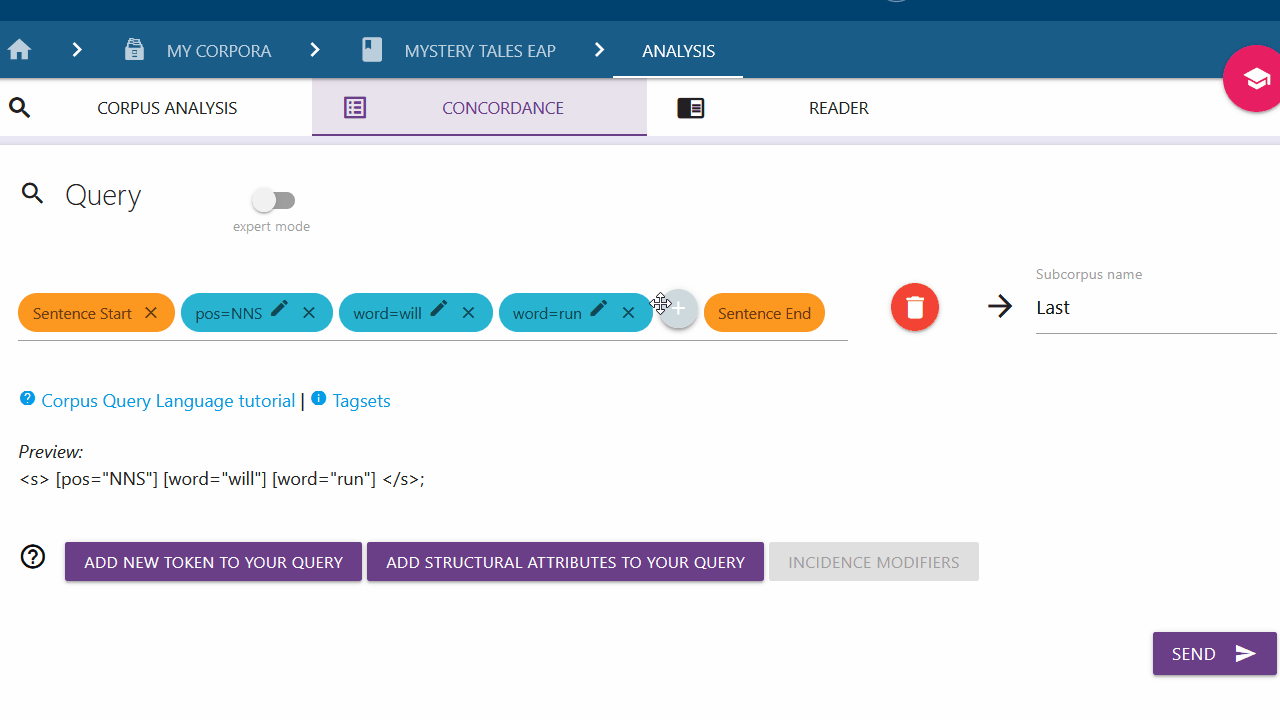
Add new token to your Query
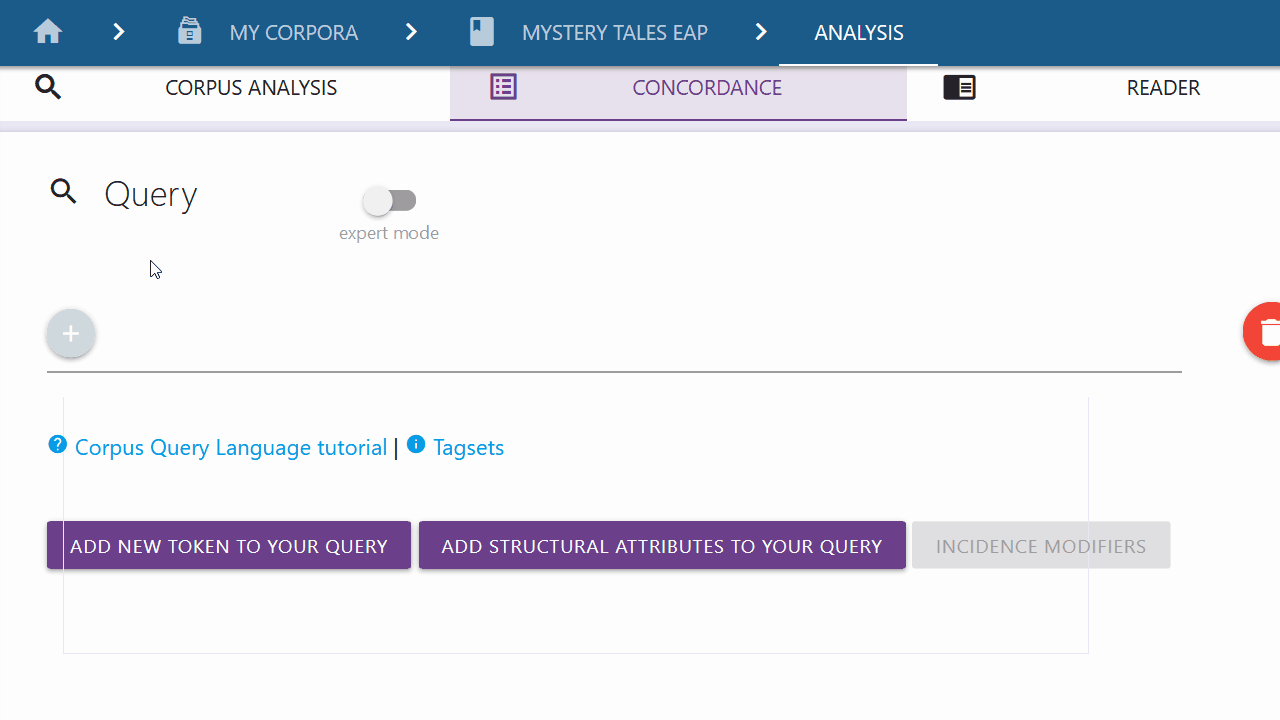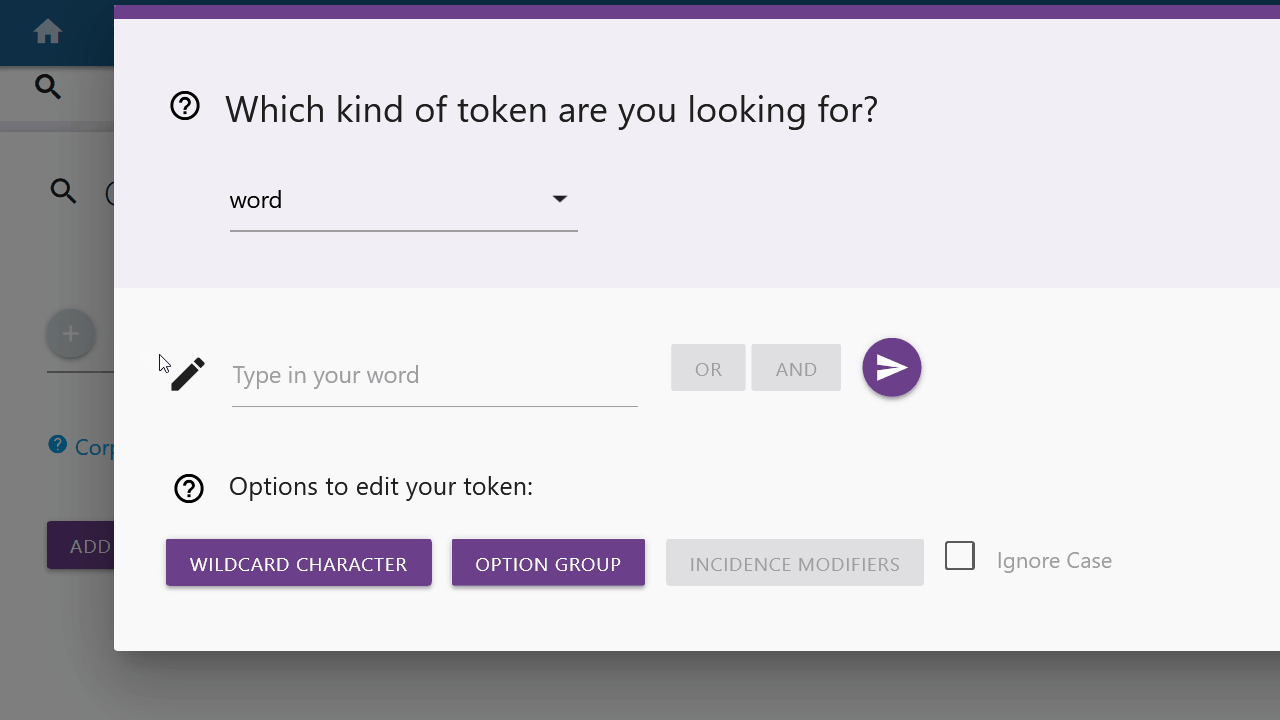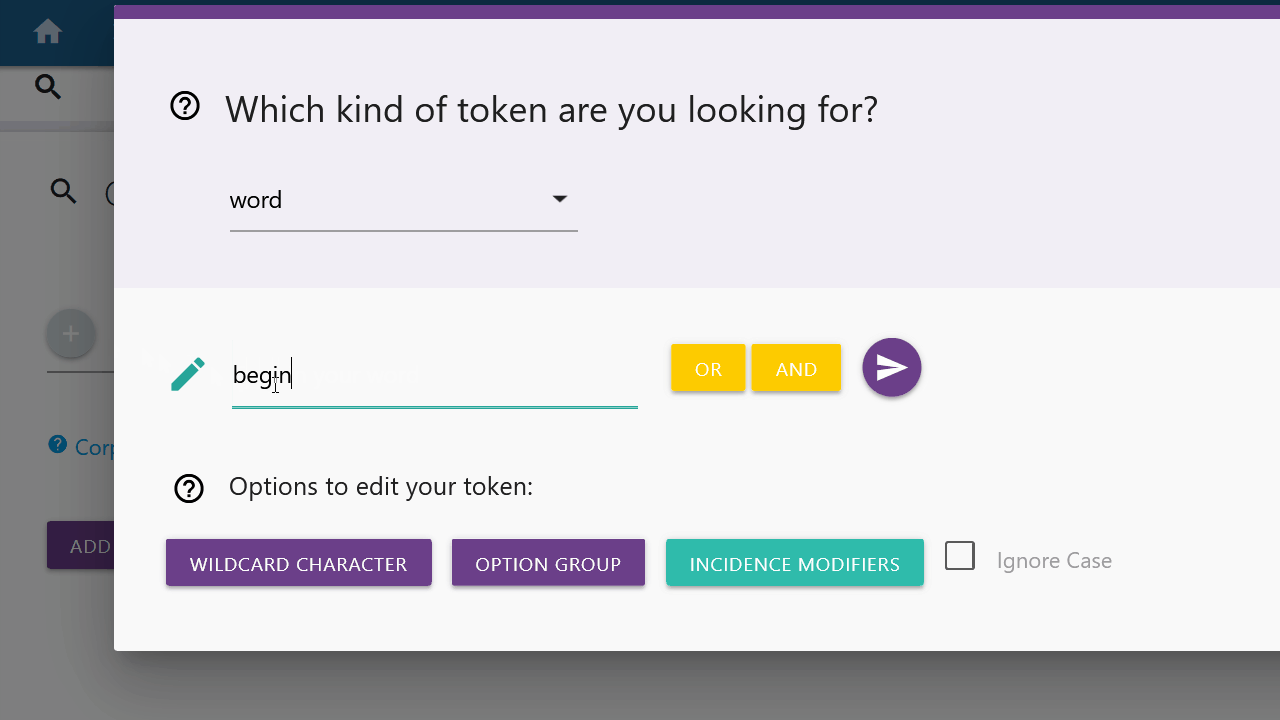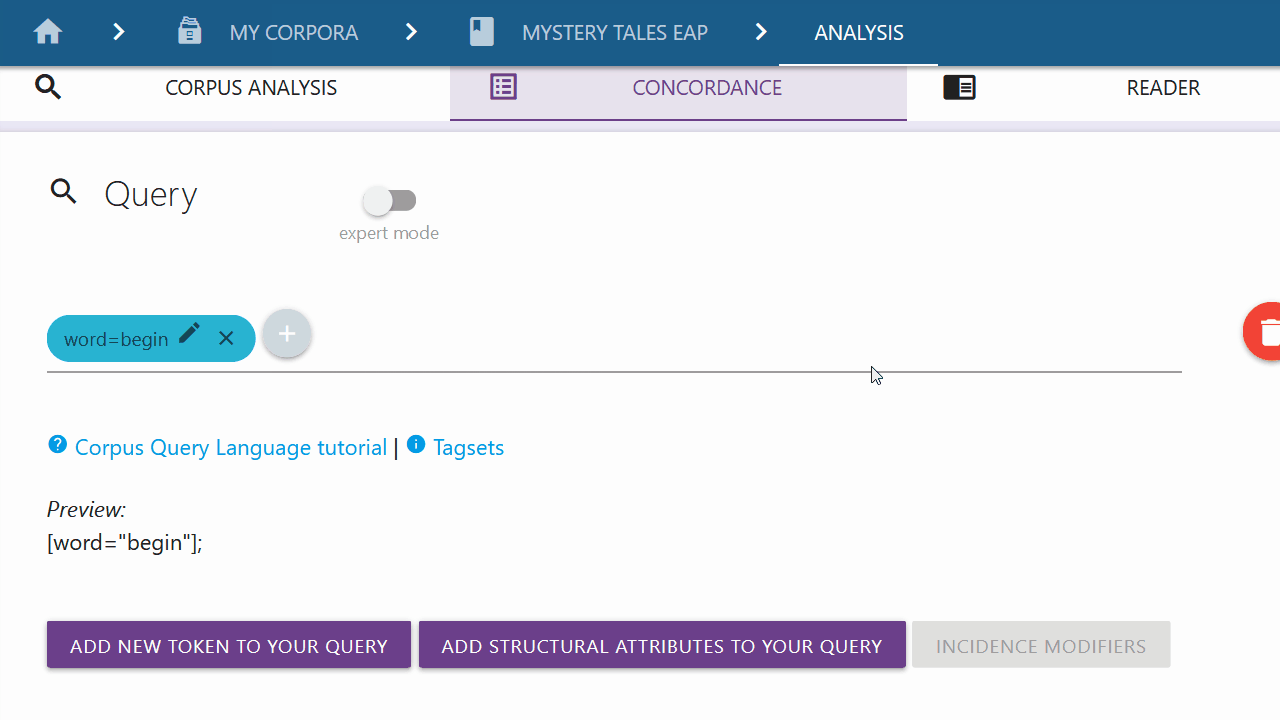
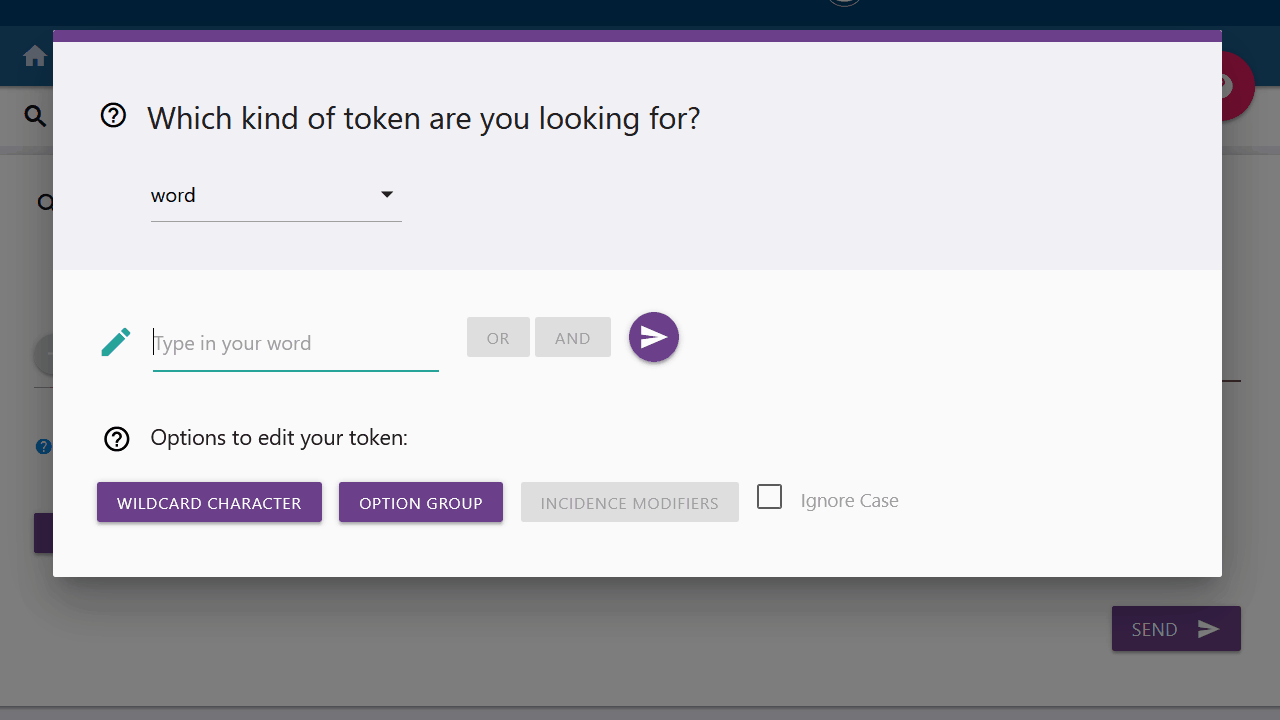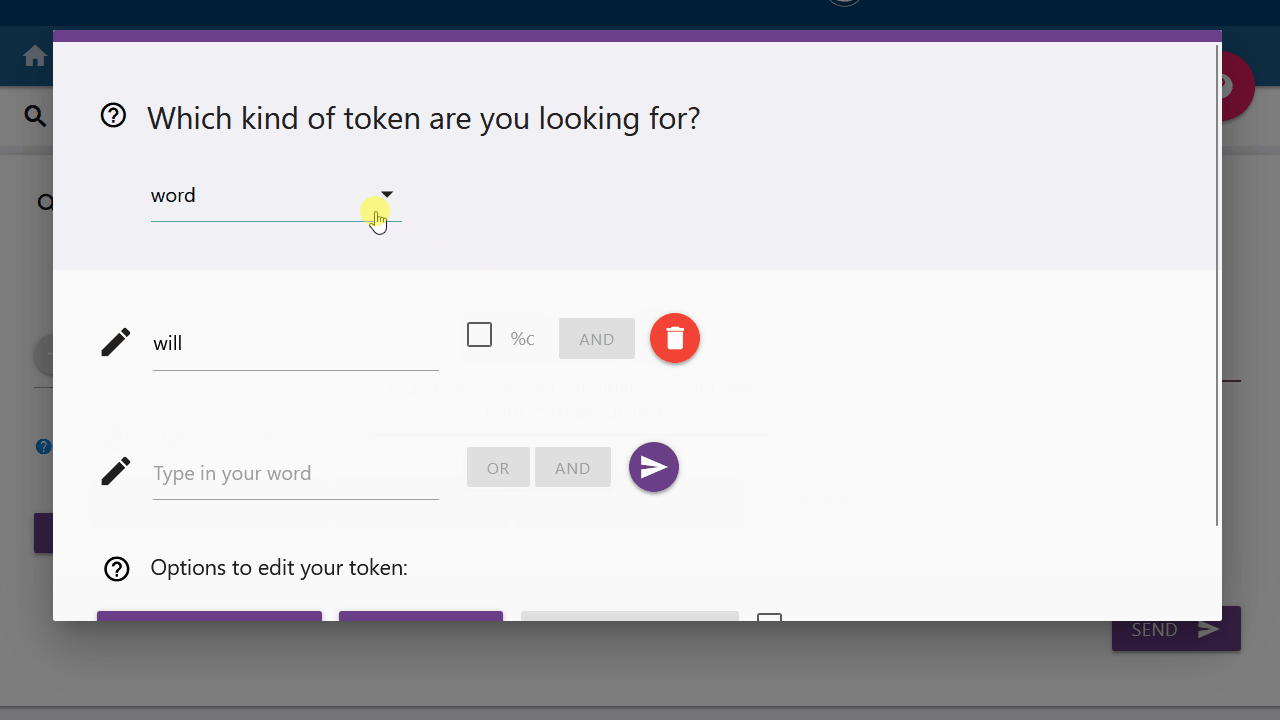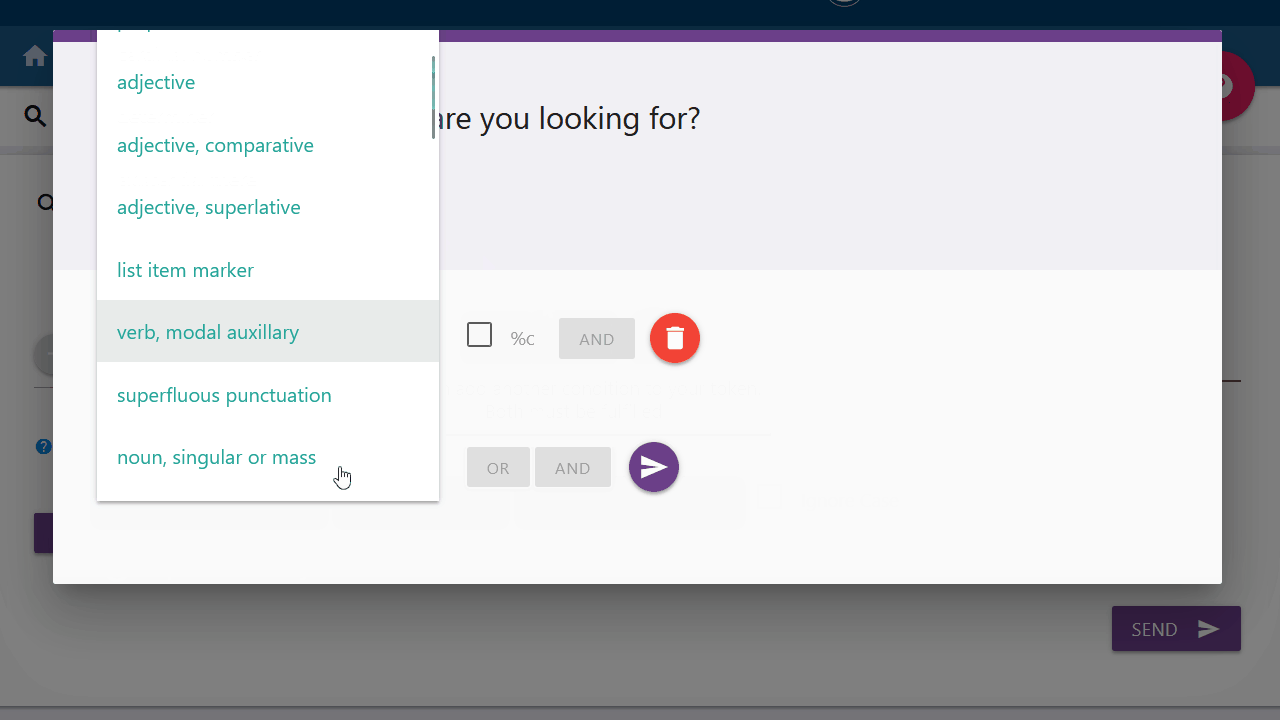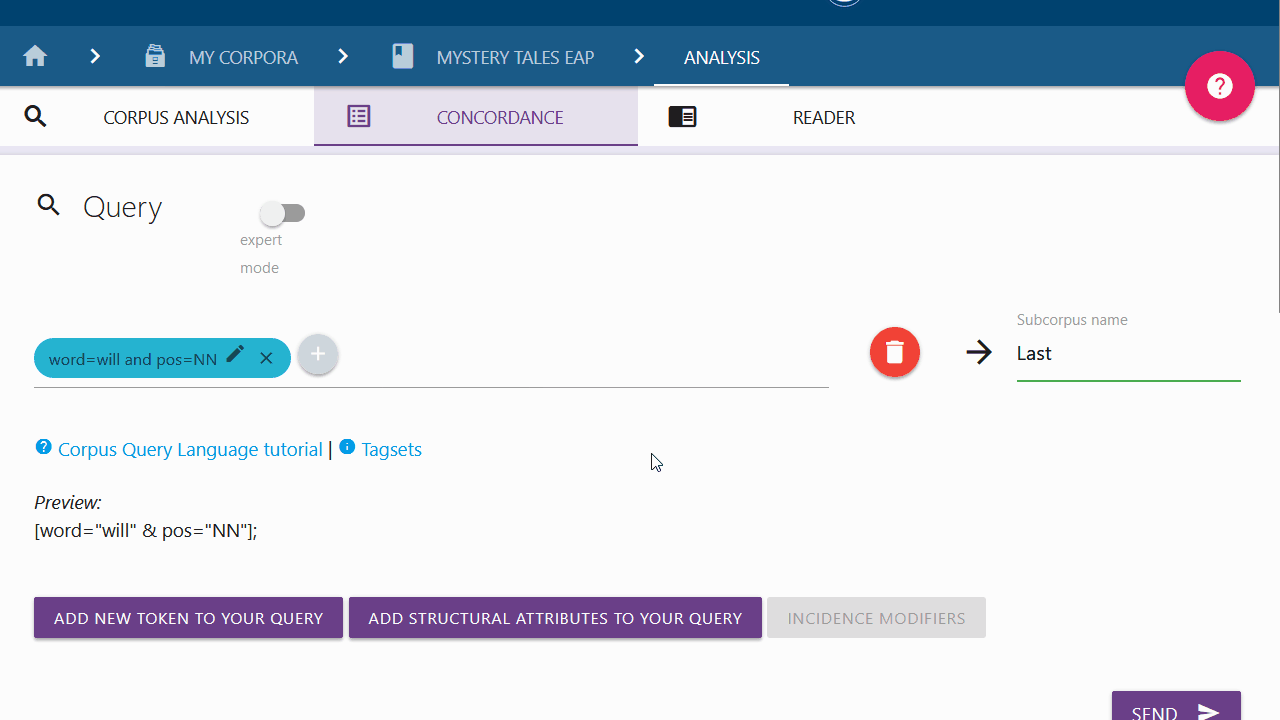
If you are only looking for a specific token, you can click on the left button and select the type of token you are looking for from the drop-down menu. By default "Word" is selected.
Word and Lemma
If you want to search for a specific word or lemma and the respective category is selected in the drop-down menu, you can type in the word or lemma of your choice in the input field. You can confirm your entry by clicking the Submit button on the right. You can also use the options below to modify your token request before pressing the submit button. These options are explained further here.
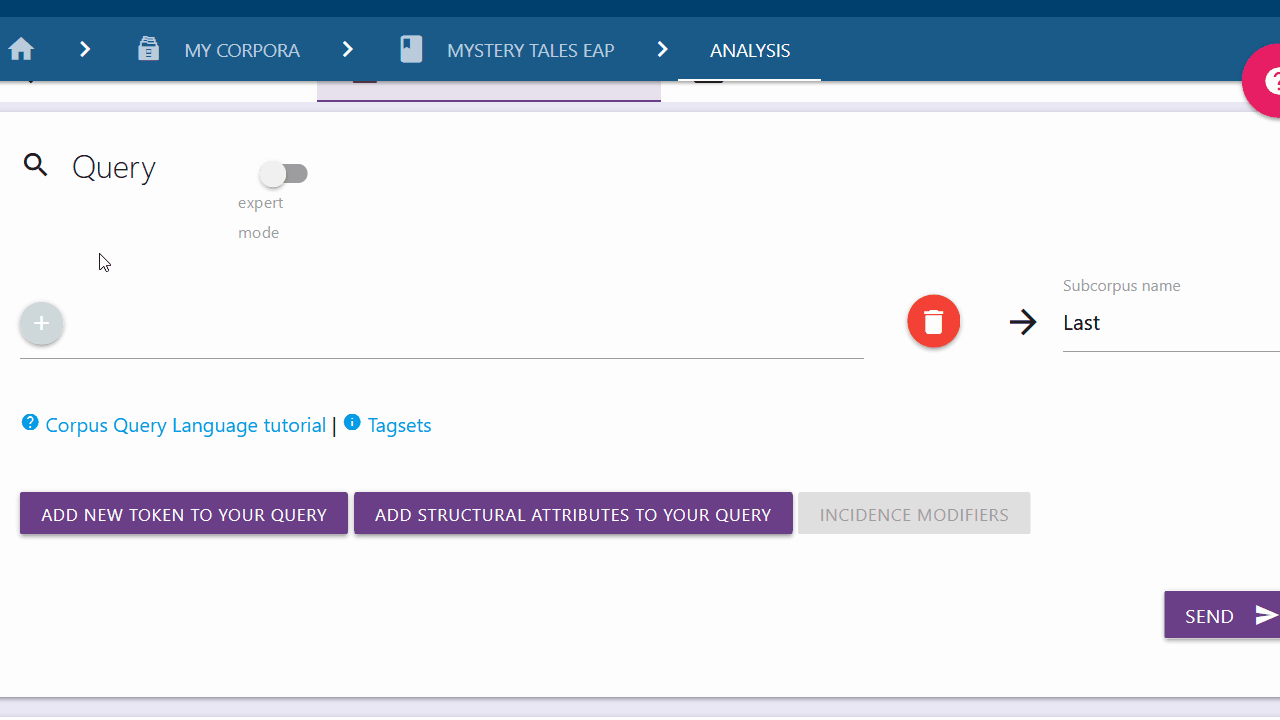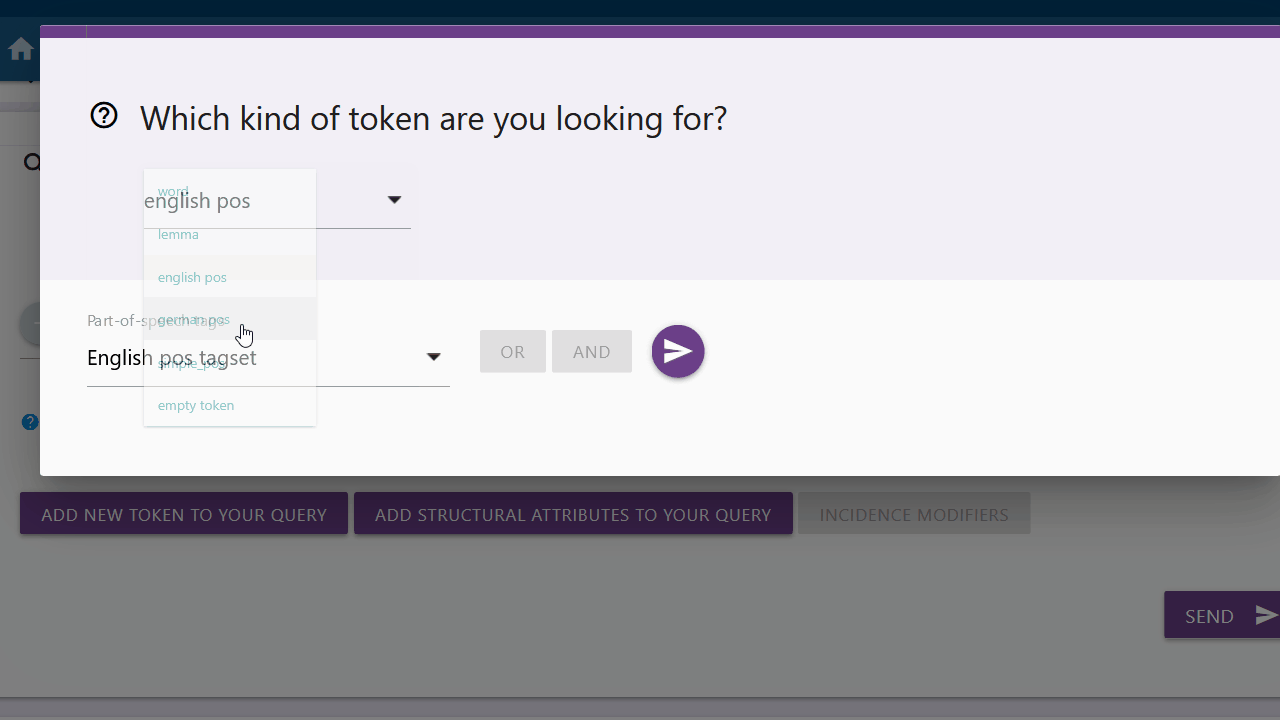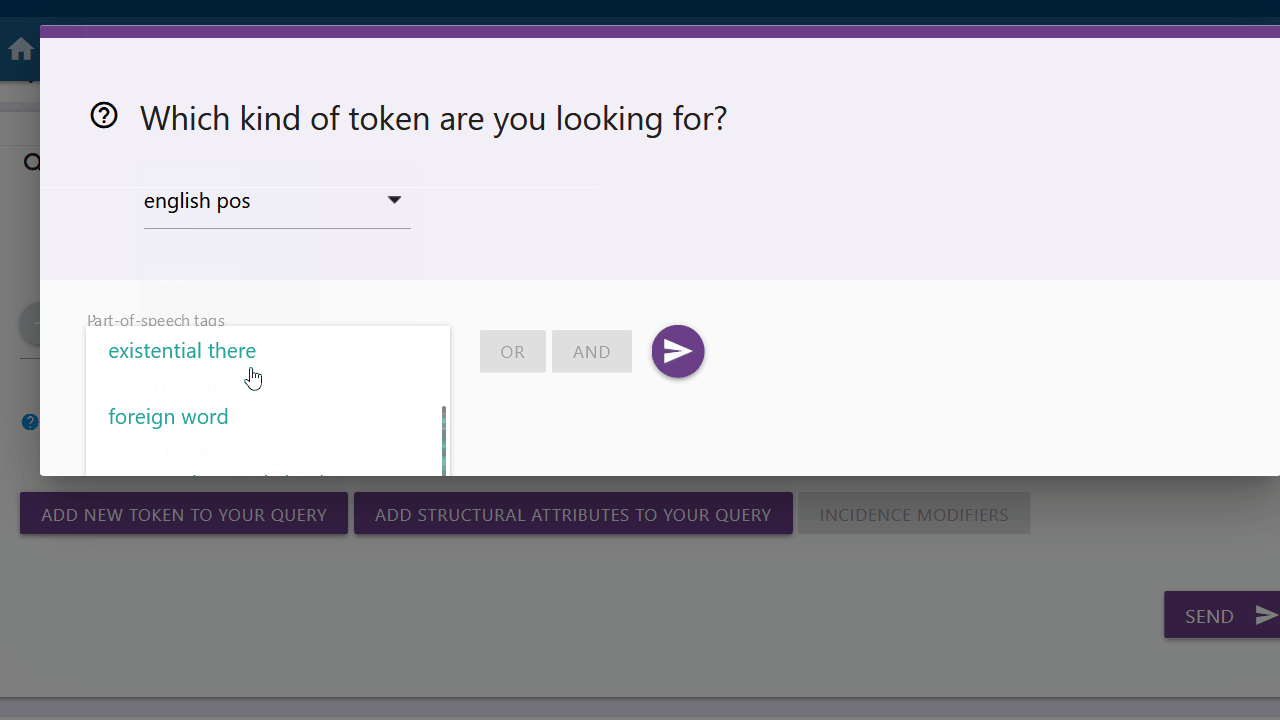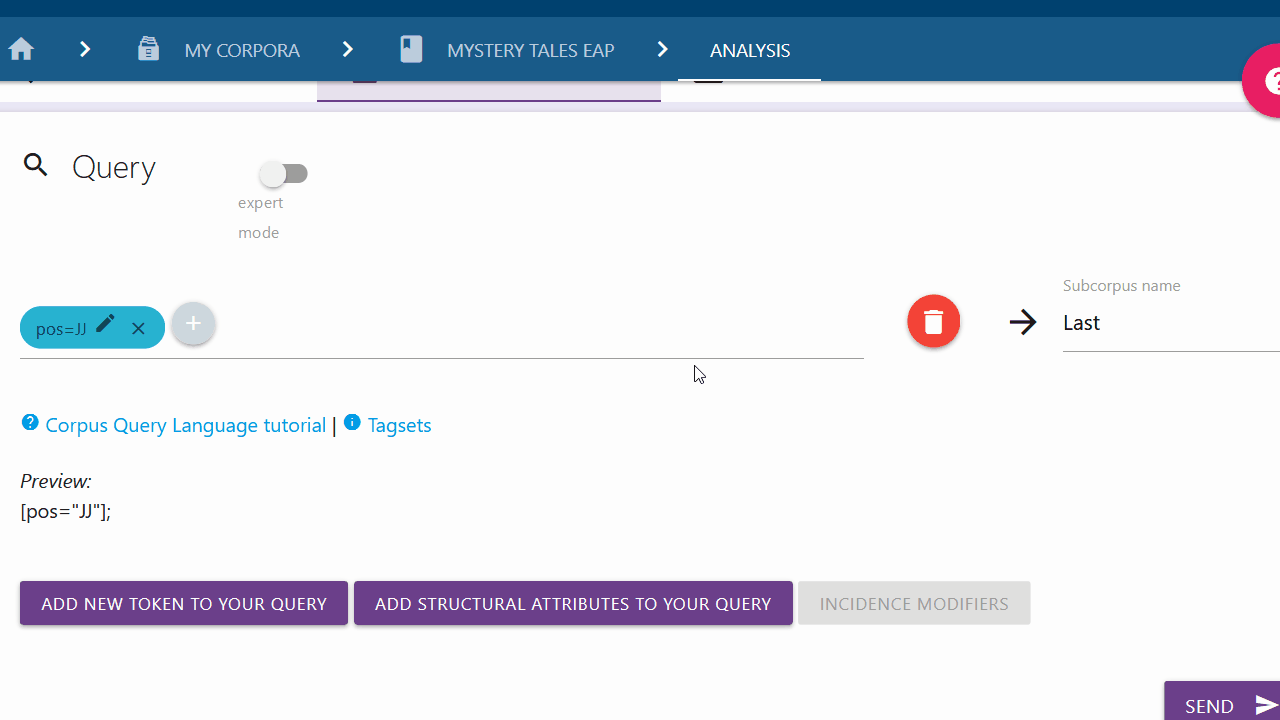
English pos, german pos or simple_pos
You can choose between the options "english pos", "german pos" and "simple_pos" to search for different parts-of-speech. You can find an overview of all tags under the "Tagsets" tab.
Empty Token
Here you can search for a token with unspecified attributes (also called wildcard token). This selection should never stand alone and should always be extended with an incidence modifier or stand in a larger query, because otherwise all possible tokens would be searched for and the program would crash.
Options for editing your query
You have the possibility to extend or specify the token you are searching for with certain factors. For this the query builder offers some fixed options. You can find more information about the options in the Corpus Query Language Tutorial.
Wildcard Character
A wildcard character replaces any character and is represented in the form of a dot.
Option Group
With an option group you can search for different variants of a token. The variants are not limited, so you can manually enter more options in the same format. "Option1" and "option2" must be replaced accordingly.
Incidence Modifiers
With the Incidence Modifiers you can determine the occurrence of single
tokens. For example you can use "?" to indicate that the token occurs either
not at all or once:
[word = "is"] [word="it"] [word="your"] [word="litte"]? [word = "dog"]
Here the word "little" should occur either once or not at all. With
[word="dogs?"] the search is for "dog "or "dogs".
Ignore Case
With the check mark at Ignore Case the upper and lower case is ignored. This is marked with a "%c". By default (if not checked) it is case sensitive.
"or" & "and"
"Or" ( | ) and "and" ( & ) are conditions you can put on a token. With "or"
one of the two conditions must be fulfilled, with "and" both conditions must be
fulfilled. For example, the word must be called "will" AND be a verb, only then
it will be displayed. Note that "and" is not responsible for lining up tokens in
this case. For this you can simply string them together:
[word="I"] [word="will" & simple_pos="VERB"] [word="go"].
Tokens that have already been added can also be modified by clicking on the corresponding pen icon. Click on the "ignore case" box, for example, and the query builder will not differentiate between upper- and lower- case letters for that respective token. New conditions added apply to the most recent token information.
Add structural attributes to your query
You can use structural attributes to search specifically for structures in the text or to further narrow down your previous search query.
Sentence
With "Sentence" (<s></s>) you can search for sentences within your text.
This search can of course be specified if you search for particular tokens or
entities between the sentence tags (<s></s>). For example, you can search for
sentences that contain only a noun, verb, and adjective.
Click on Sentence to add the sentence chips: Sentence Start
and Sentence End.
These mark where the sentence starts and ends. Use drag-and-drop to place them accordingly. When
the Sentence attribute is added, the input marker will automatically be
moved between the sentence chips. Use drag-and-drop as needed to continue your query
at a different position.
Entities
With entities, i.e. units of meaning, you can search for text sections that
contain more specific information, for example, persons, dates, or events. The
codes for these categories can be selected using the drop-down menus. You can find an explanation of
these abbreviations under the tab "Tagsets".
You can also search for unspecified entities by selecting "Add entity of any type".
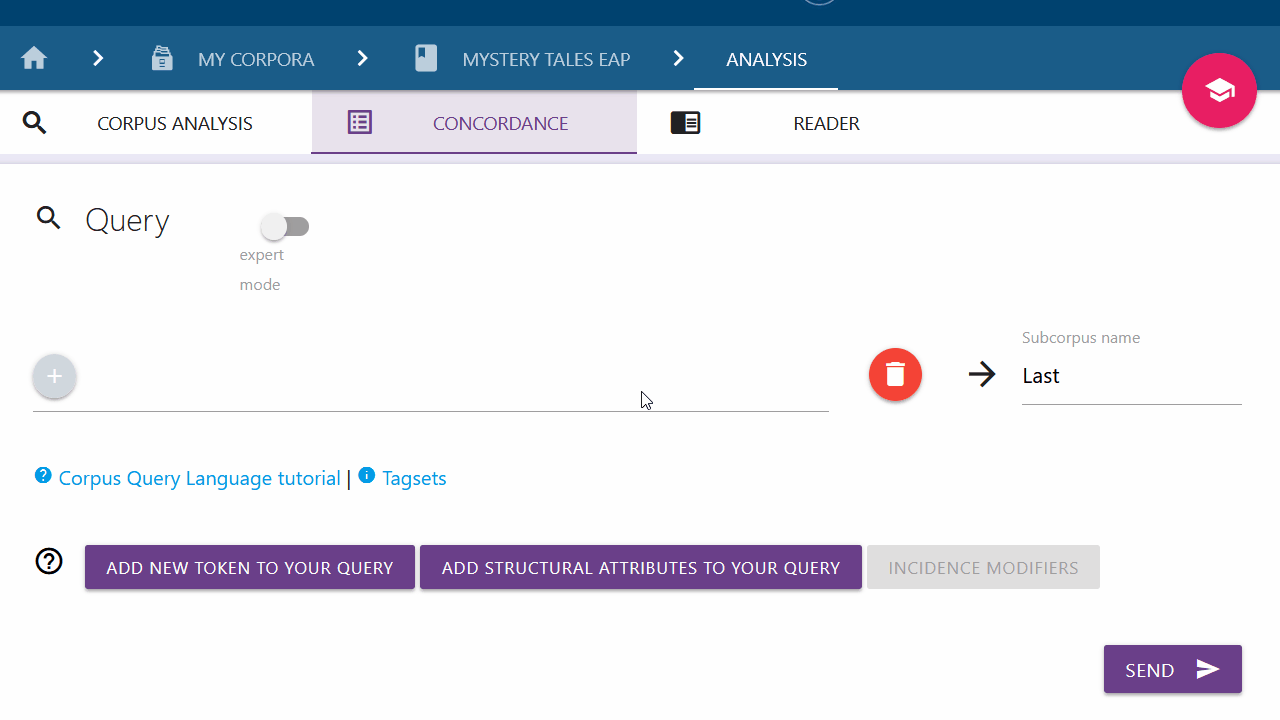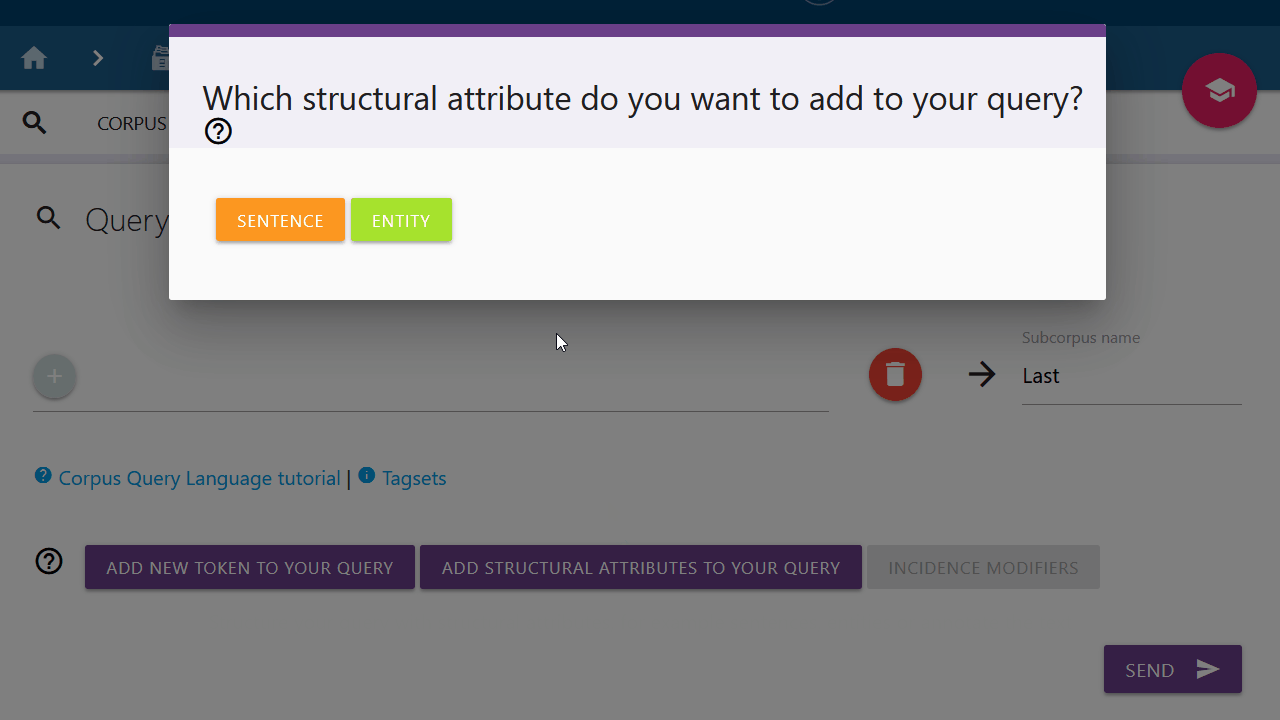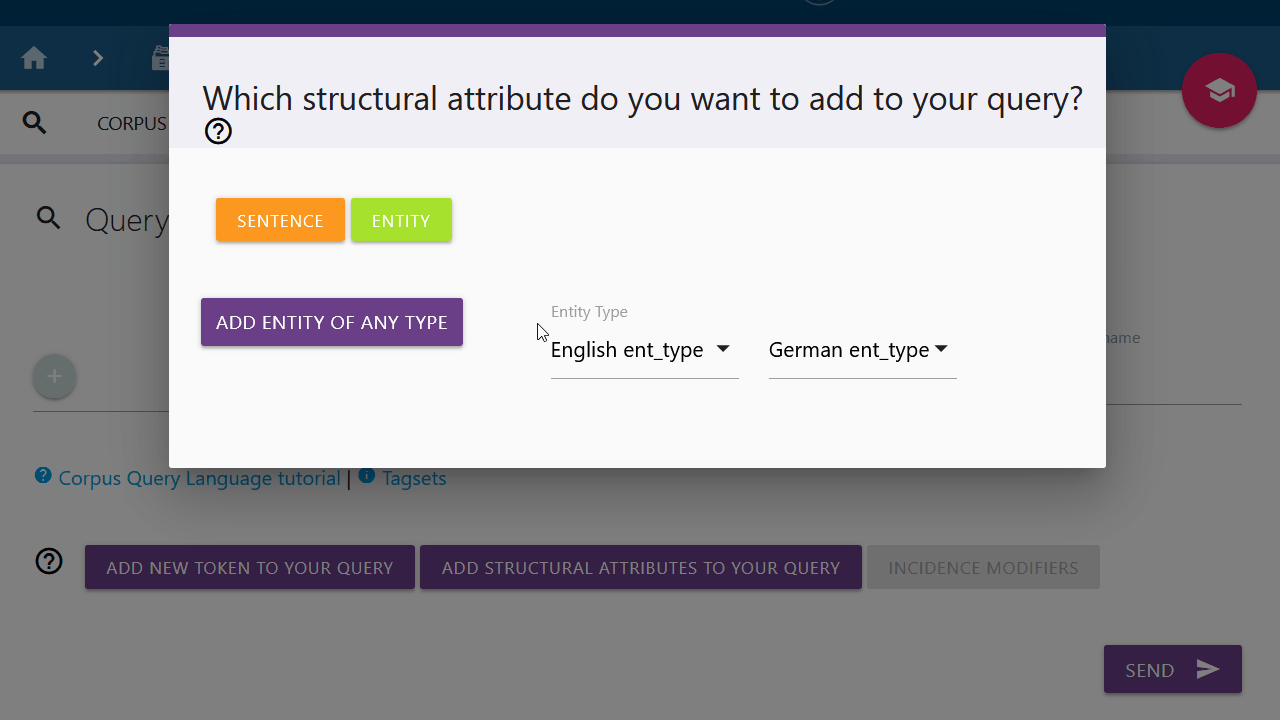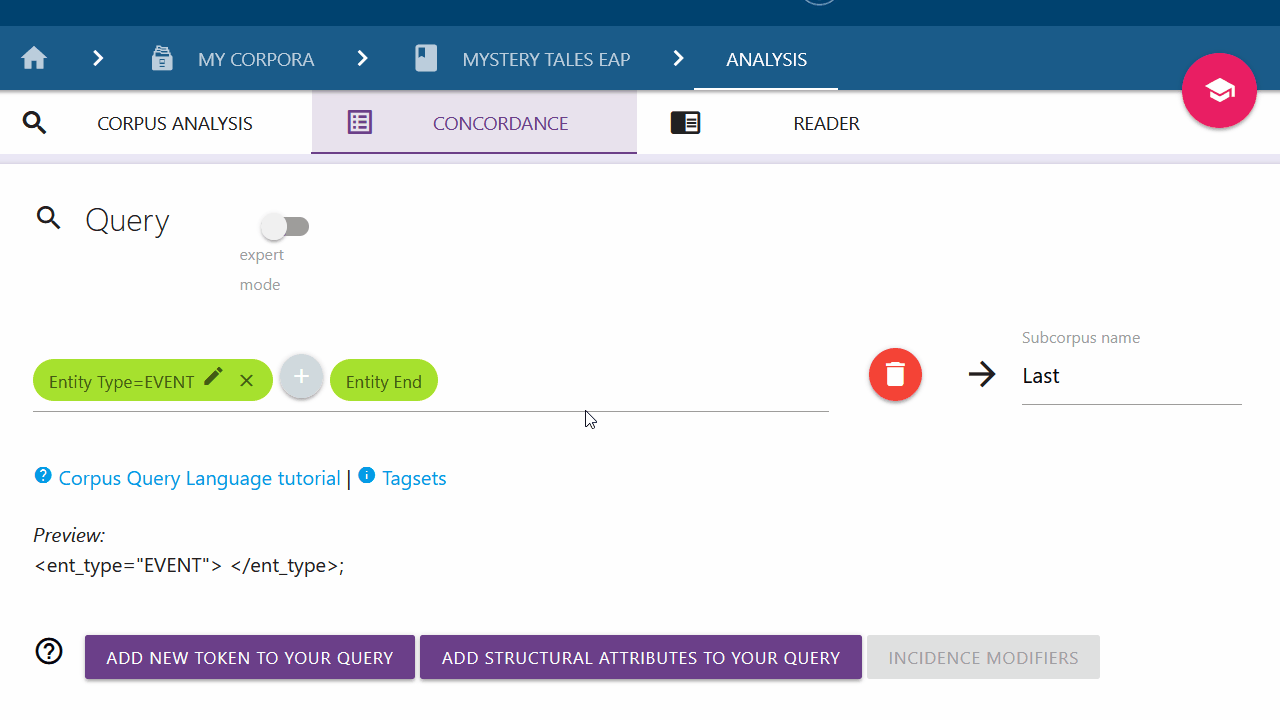
Click on the Entity button to add the entity chips Entity Type= and Entity End.
The entity type can be changed by clicking on the pen symbol on the chip. When the Entity attribute is added, the input marker will automatically be moved between the entity chips. Use drag-and-drop as needed to continue your query at a different position.
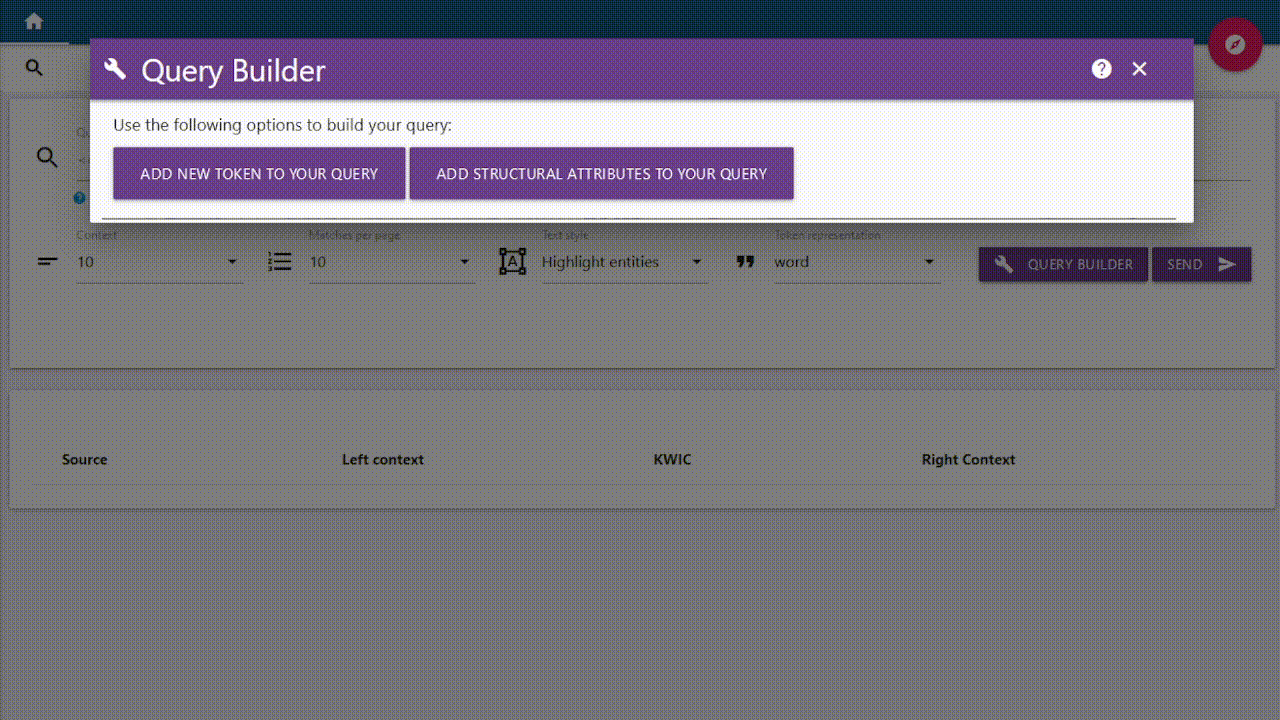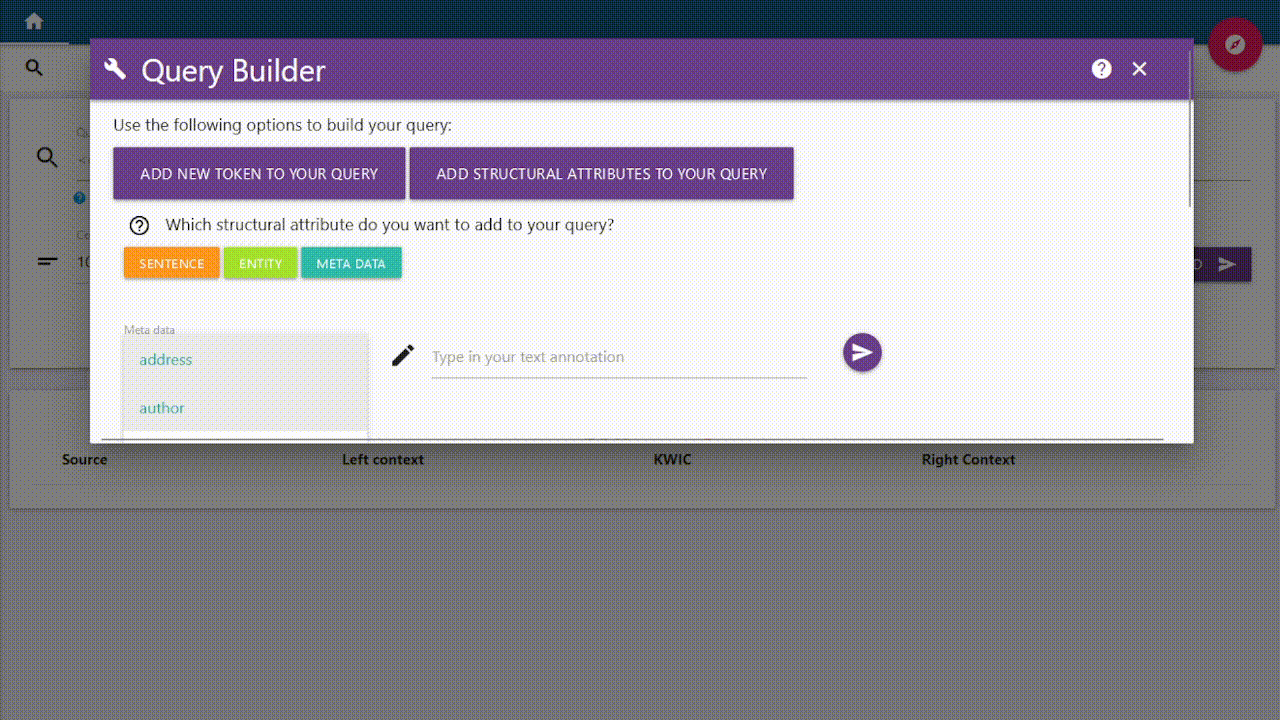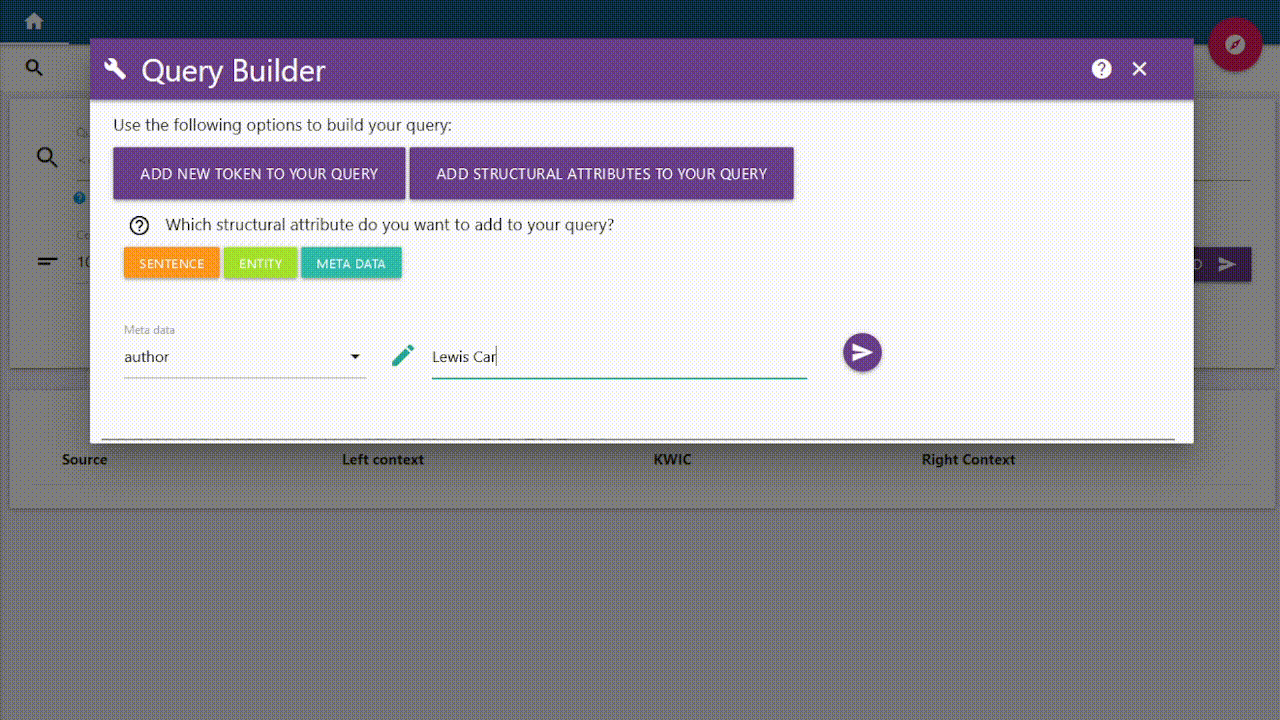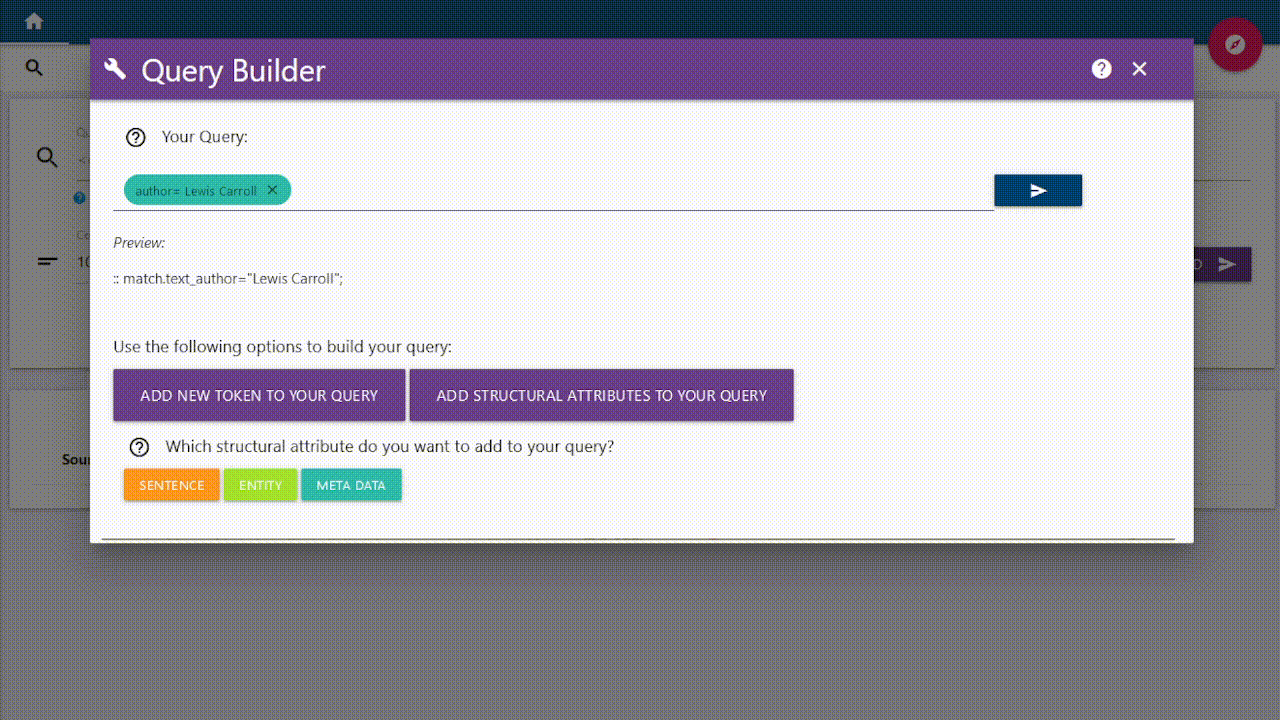
Meta Data (currently unavailable)
The meta data function is being worked on and cannot currently be used!
With the meta data you can annotate your text and add specific conditions.
You can select a category on the left and enter your desired value on the right.
The selected metadata will apply to your entire request and will be added at the end.
General Options of the query builder
You have several options to edit your query after adding it to the preview.
Editing the elements
You can edit your query chips by clicking on the pen icon.
Deleting the elements
You can delete the added elements from the query by clicking the X behind the respective content.
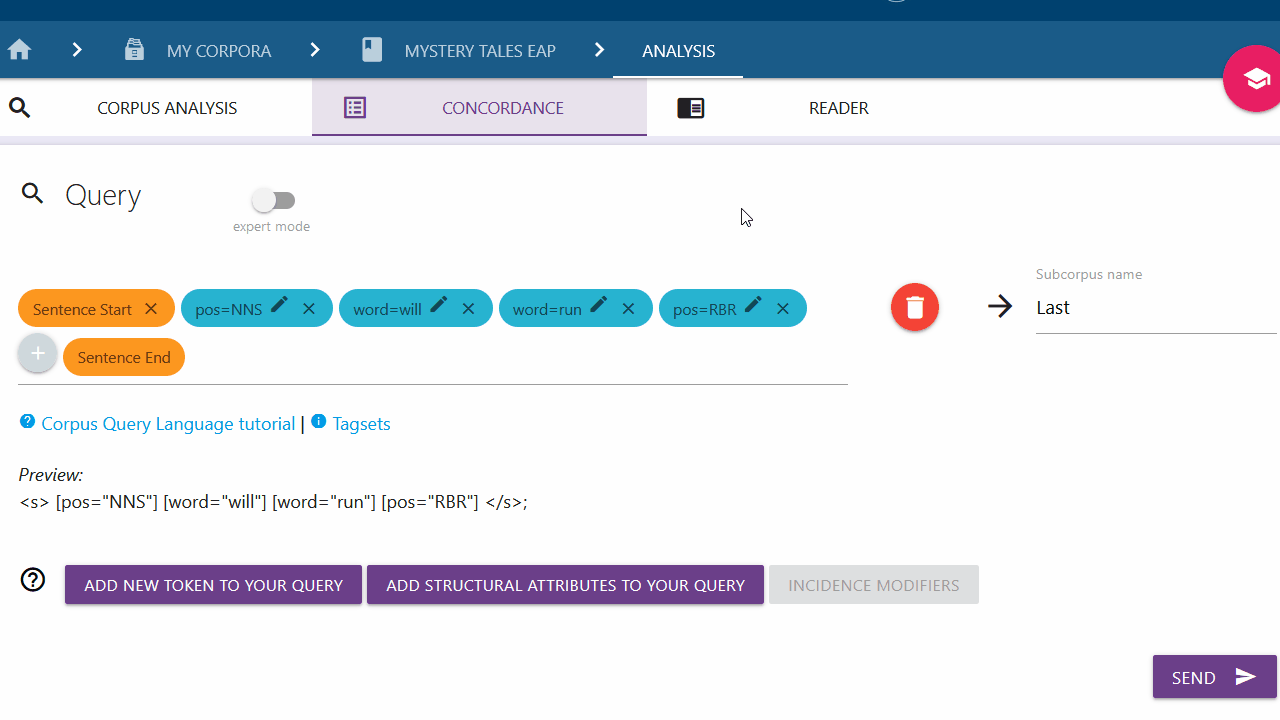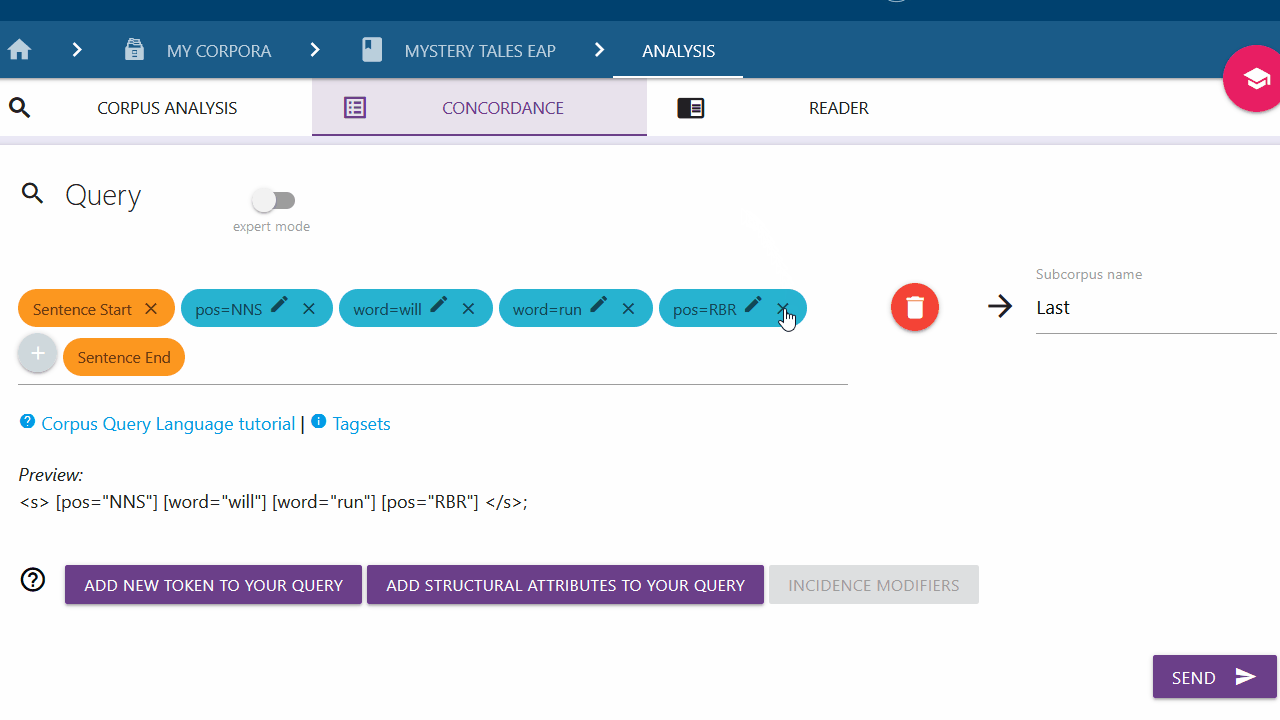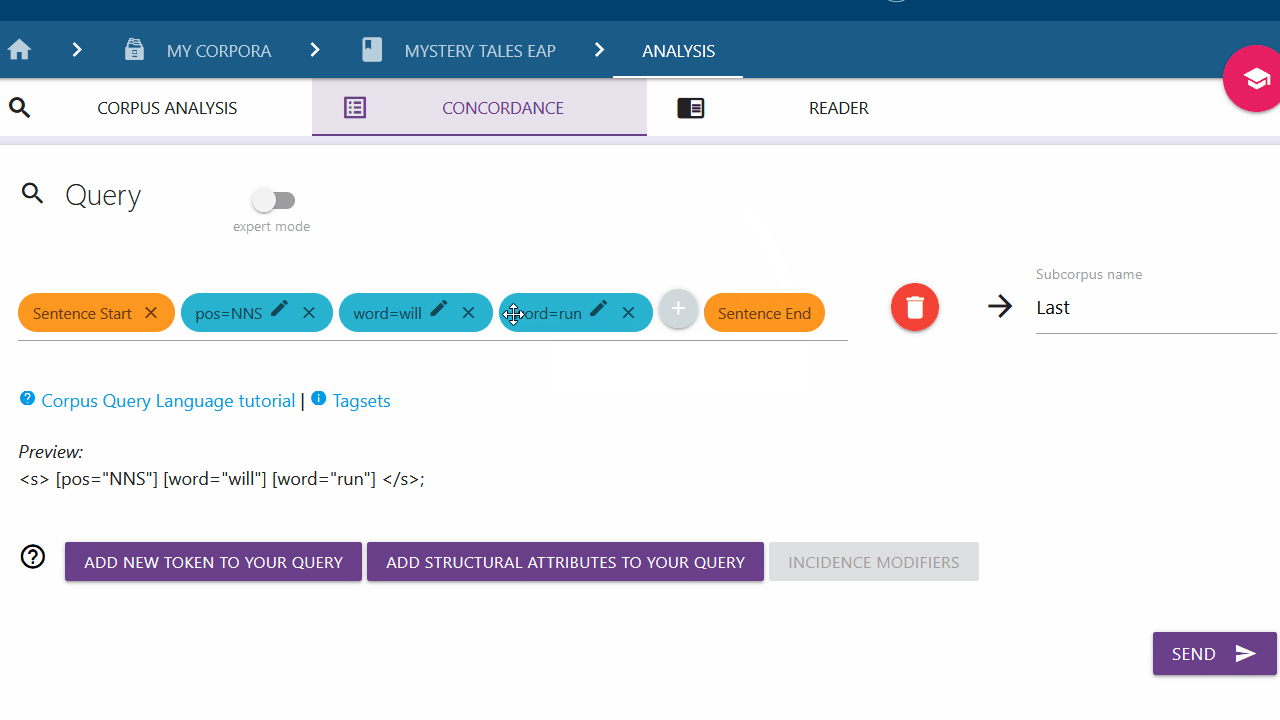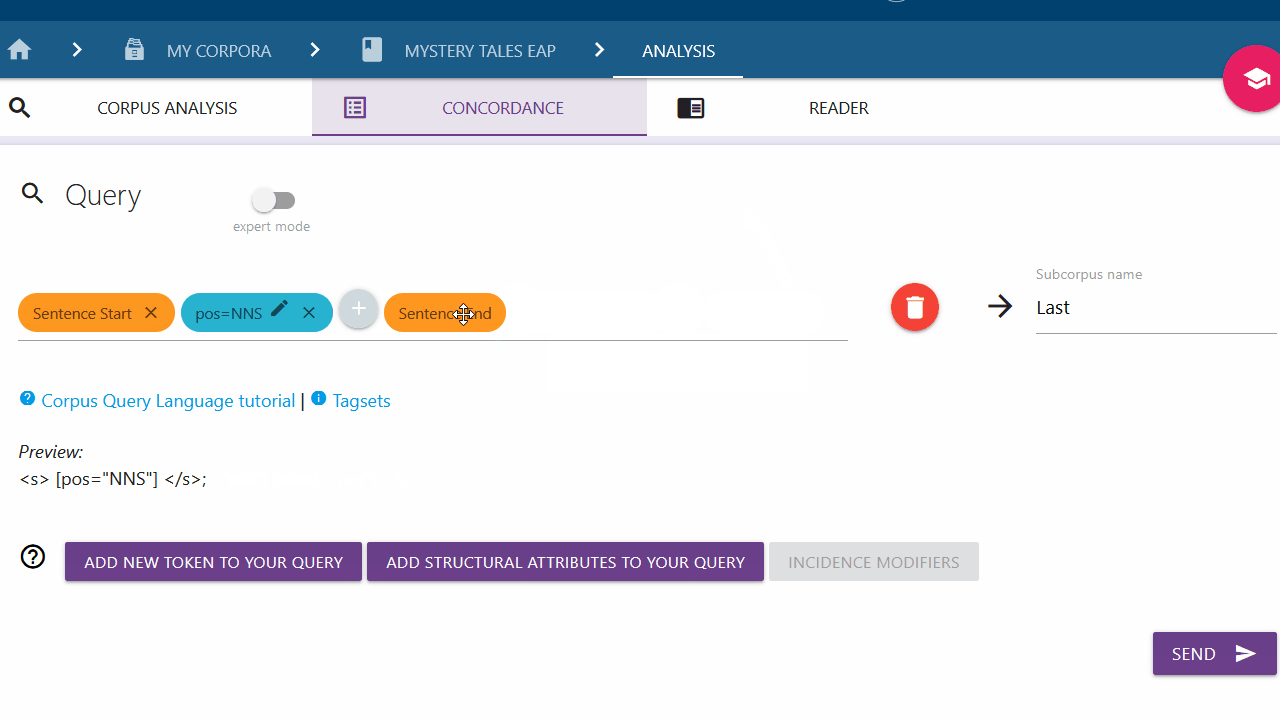
Move the elements of your query
You can drag and drop elements to customize your query.
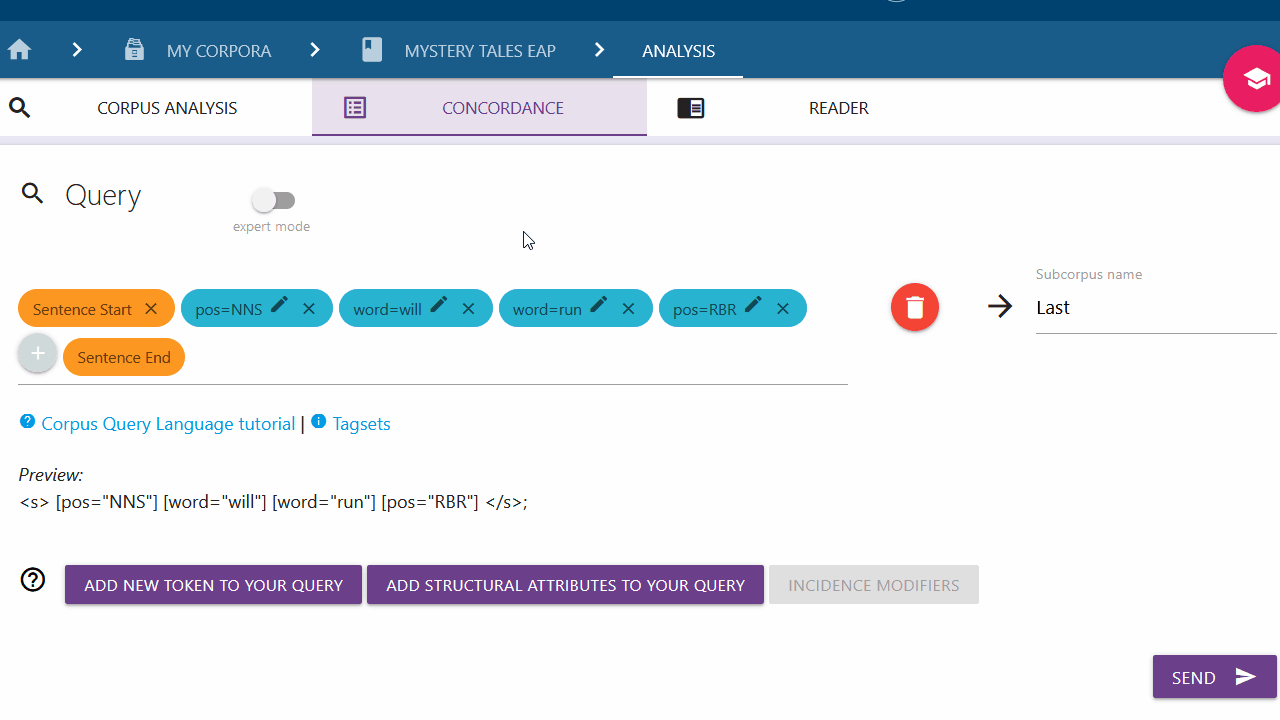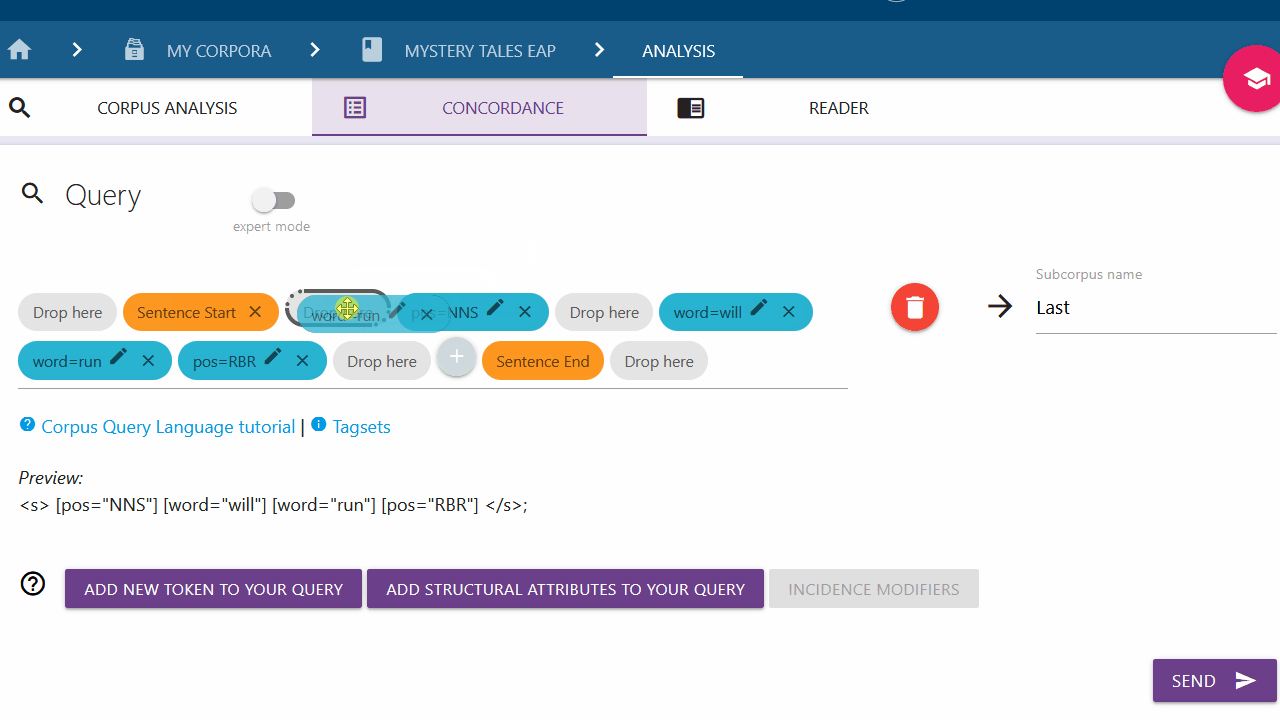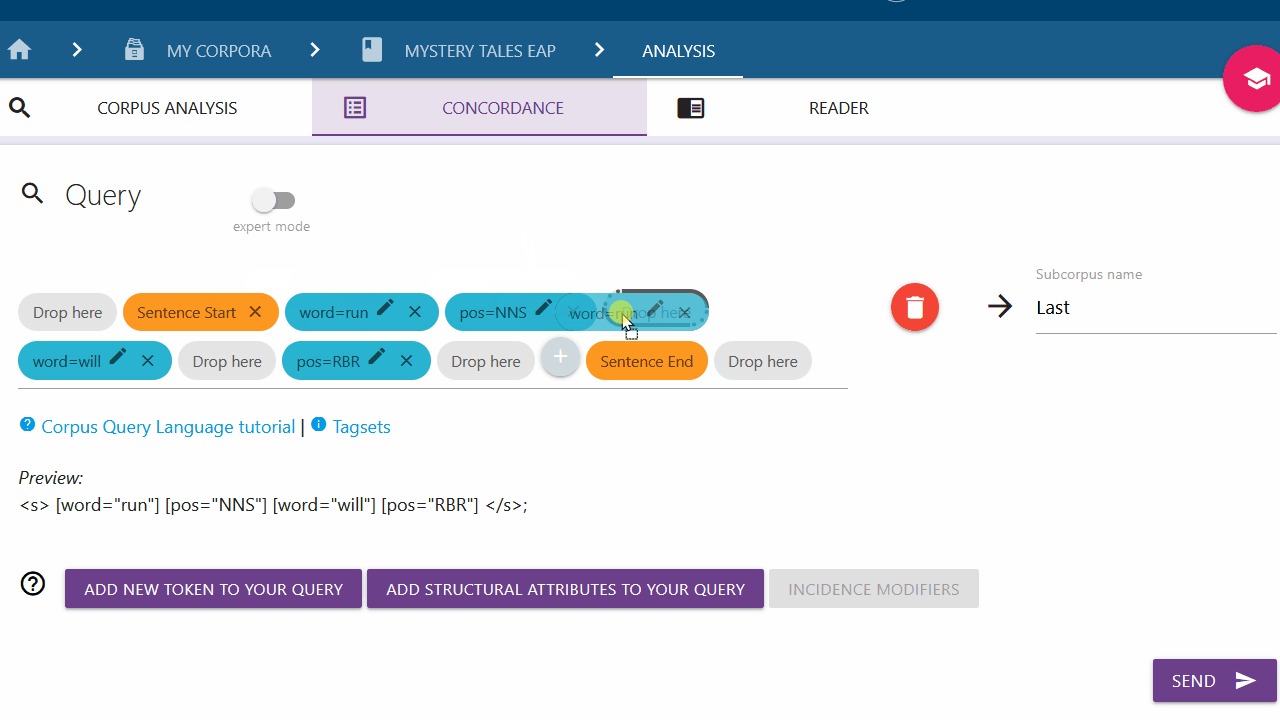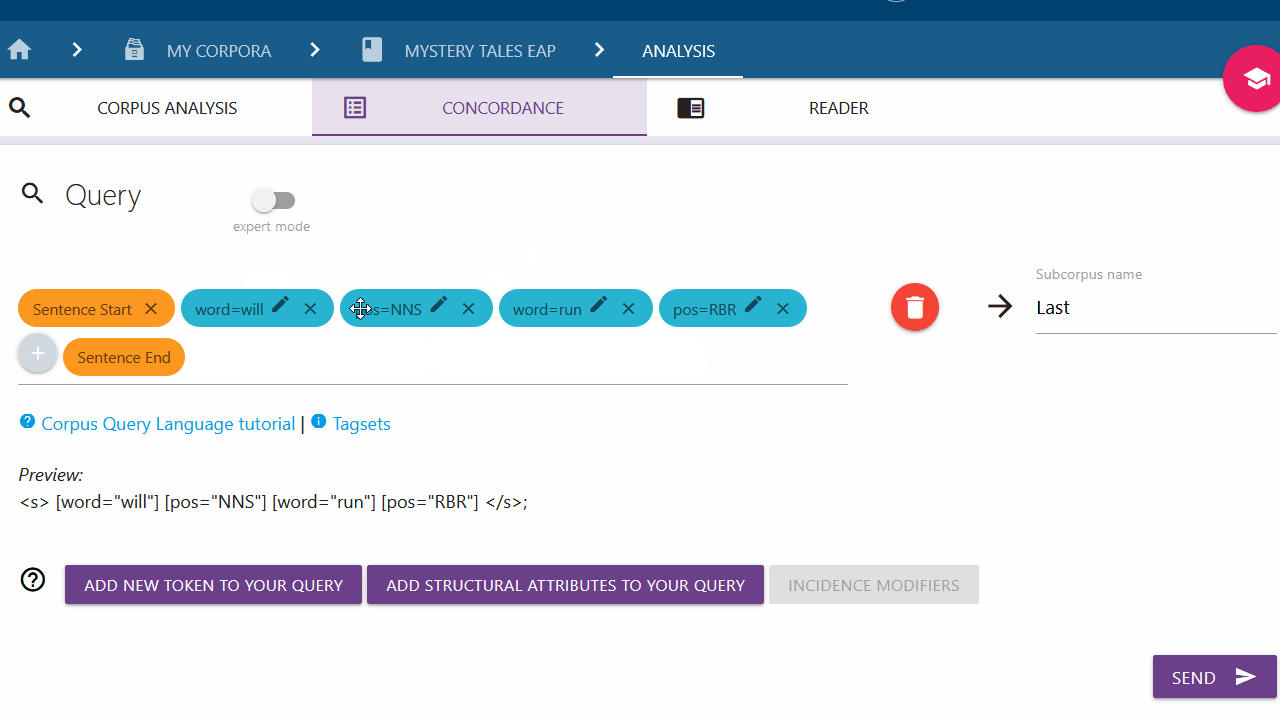
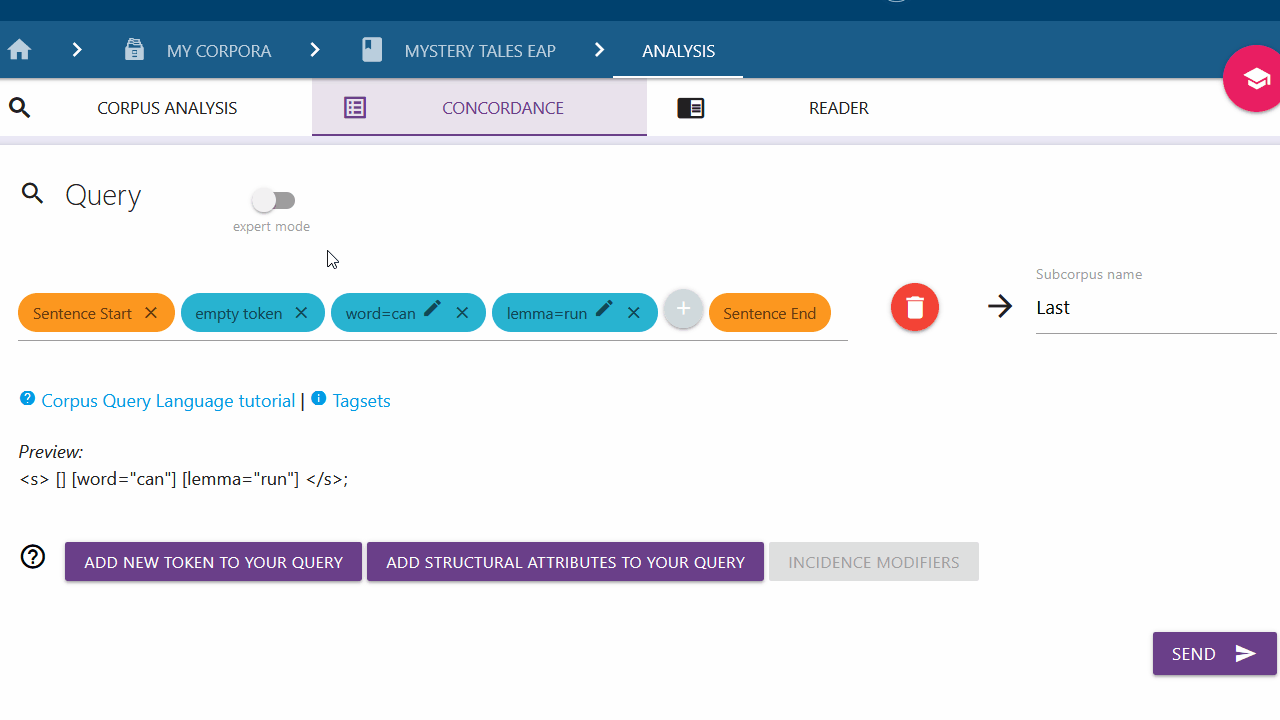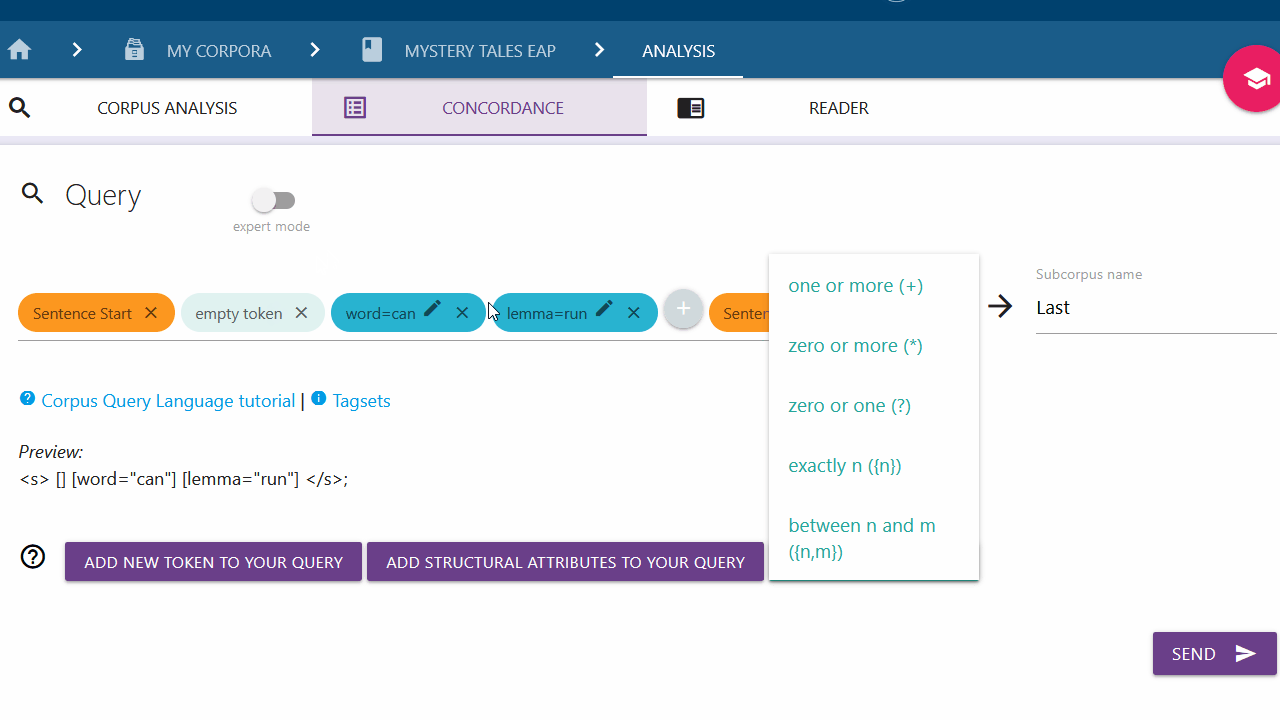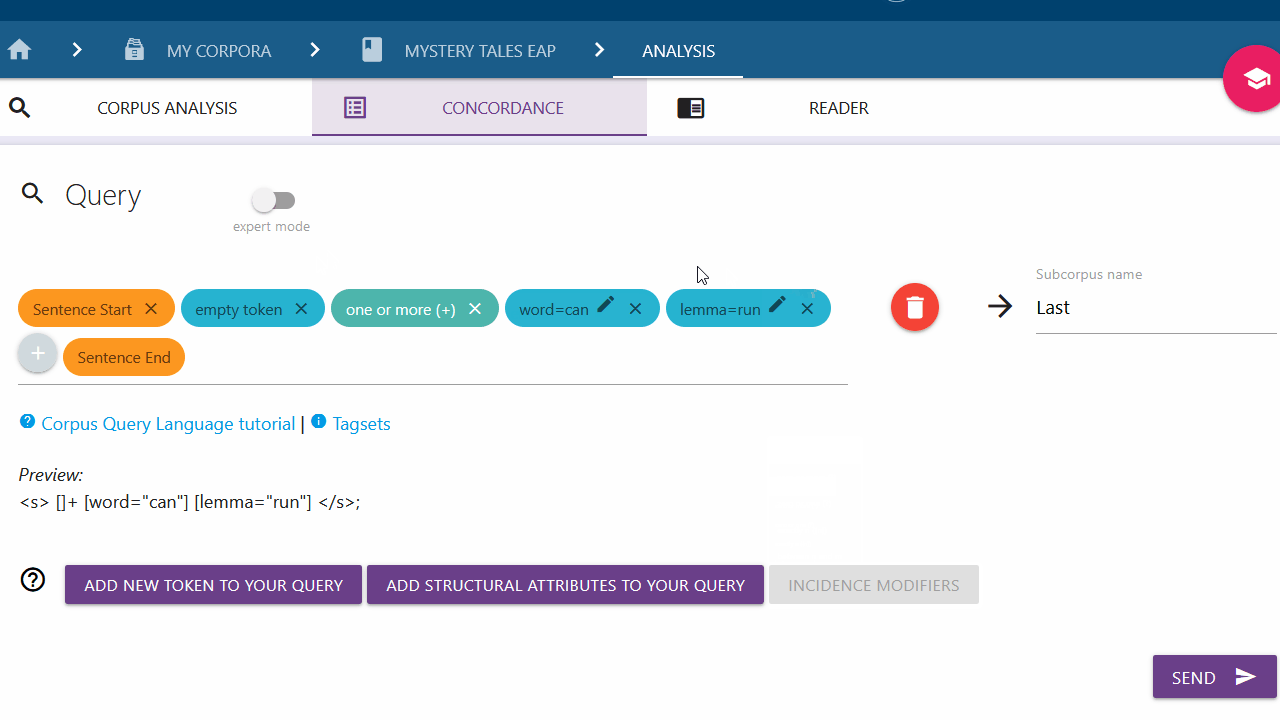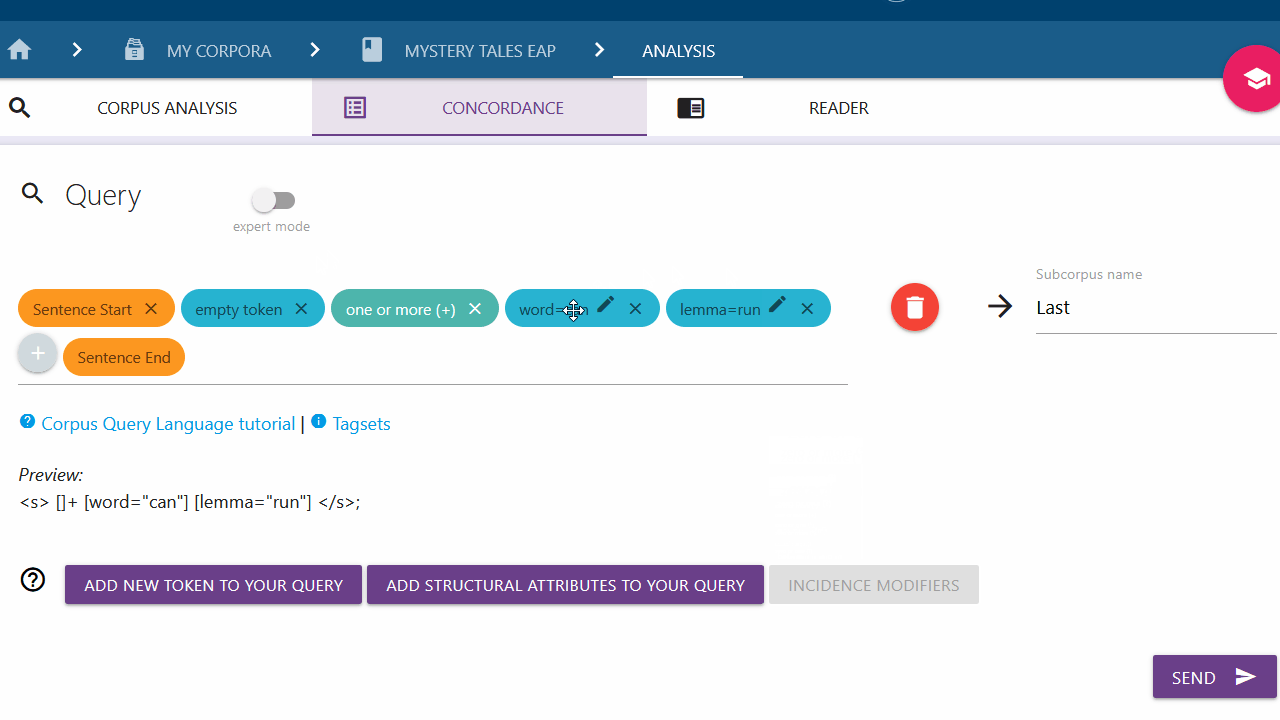
Setting an incidence modifier
With the incidence modifier option, you can specify the amount of times a token should appear in your query. This is particularly relevant for empty tokens (tokens with unspecified attributes). Click on a token (blue chip) and select the desired option from the list to add an incidence modifier. To close the list without adding anything, click on the token again.
Switching between Query Builder and Expert mode
To work with the plain Corpus Query Language instead of using the Query Builder, click on the "expert mode" switch. Your query can be entered into the input field. All elements previously added will be carried over into expert mode. Click on the switch again to switch back to the Query Builder if desired. All recognized elements will be parsed into chips; those not recognized will be deleted from the query.
Tagsets
-
simple_pos
- ADJ: adjective
- ADP: adposition
- ADV: adverb
- AUX: auxiliary verb
- CONJ: coordinating conjunction
- DET: determiner
- INTJ: interjection
- NOUN: noun
- NUM: numeral
- PART: particle
- PRON: pronoun
- PROPN: proper noun
- PUNCT: punctuation
- SCONJ: subordinating conjunction
- SYM: symbol
- VERB: verb
- X: other